What happens when you give domain experts — clinicians, data scientists, academics, and industry professionals — a week to solve real-world problems with an agentic data platform? You get pipelines that rethink how clinic coordinators recover missed outpatient slots, how behavioral health care teams intervene before patients fall through the cracks, and how clinical trial sites move from chaos to activation.
Our Agentic Data & Analytics Hackathon challenged participants to build end-to-end agentic data pipelines using Ascend and Otto, our agentic AI assistant. Thirteen builders submitted projects spanning healthcare, fintech, climate science, fraud detection, and more. The results weren't demos. They were working systems — scheduled, automated, and designed to be used.
Here's a look at what our top builders shipped and what they learned along the way. (If you missed our last hackathon, the bar was already high — this cohort cleared it.)
First Place: Nidhi Uchil
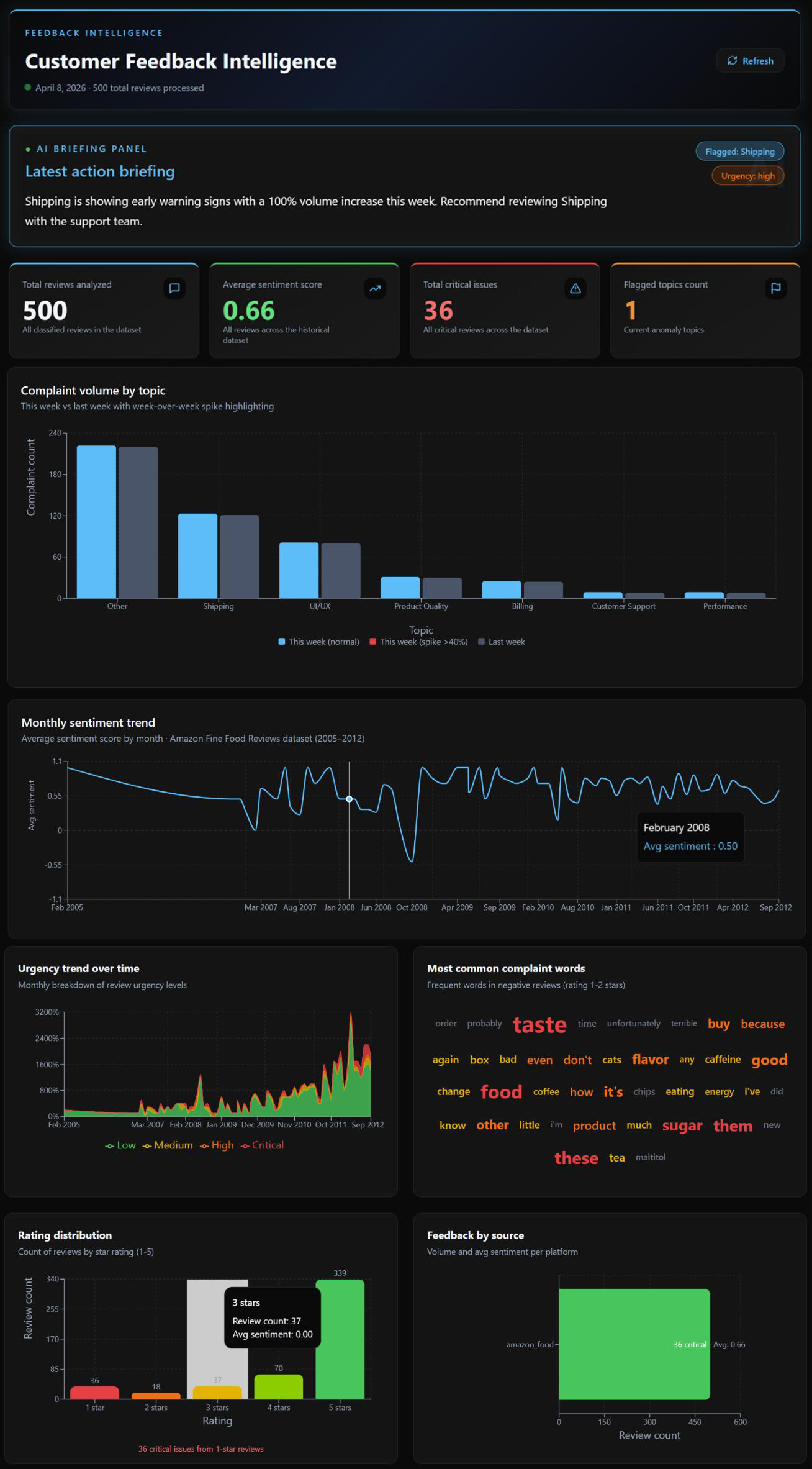
Customer Feedback Intelligence
The build
Nidhi built a 7-component end-to-end pipeline that ingests real customer review data, classifies every review with AI-powered sentiment scoring and topic classification, detects anomalies, and generates a plain-English briefing — fully automated, running daily at 7 AM UTC.
What set this project apart wasn't just the pipeline. Before writing a single component, Nidhi built a complete agentic harness inside the /otto rules directory: a glob-scoped Python standards rule enforcing docstrings and vault usage across every .py file automatically, a keyword-scoped vocabulary rule that enforced controlled topic labels whenever Otto touched classification code, a custom Feedback Quality Agent at temperature 0.1 for deterministic data validation, and a /learning.md command that captured session insights back into rule files — making the system smarter with every build session.
Three automation YAMLs completed the picture: daily scheduling, failure diagnosis with root cause analysis, and critical spike notifications — all triggered with zero manual intervention.
The pipeline detected a real anomaly in the demo data: a 100% week-over-week volume increase in Shipping complaints, 8 critical reviews, urgency: high. The automated briefing surfaced it before anyone had to ask.
What makes it stand out
This project is the clearest demonstration in the cohort of what it means to build with Otto rather than just using Otto. The controlled vocabulary rule — two minutes of work — made the entire aggregation layer function. Without it, "shipping delay" and "late delivery" would appear as separate topics, noise instead of signal. One rule, compounding everywhere downstream.
"The /otto directory is the real product. By the end, the rules library was more valuable than any individual component. Every correction, every pattern, every standard lived there, and each session started smarter than the last."
— Nidhi Uchil
Second Place: Dr. Tahmina Zebin
Clinic Patient DNA Management: AI-Assisted Slot Recovery Pipeline
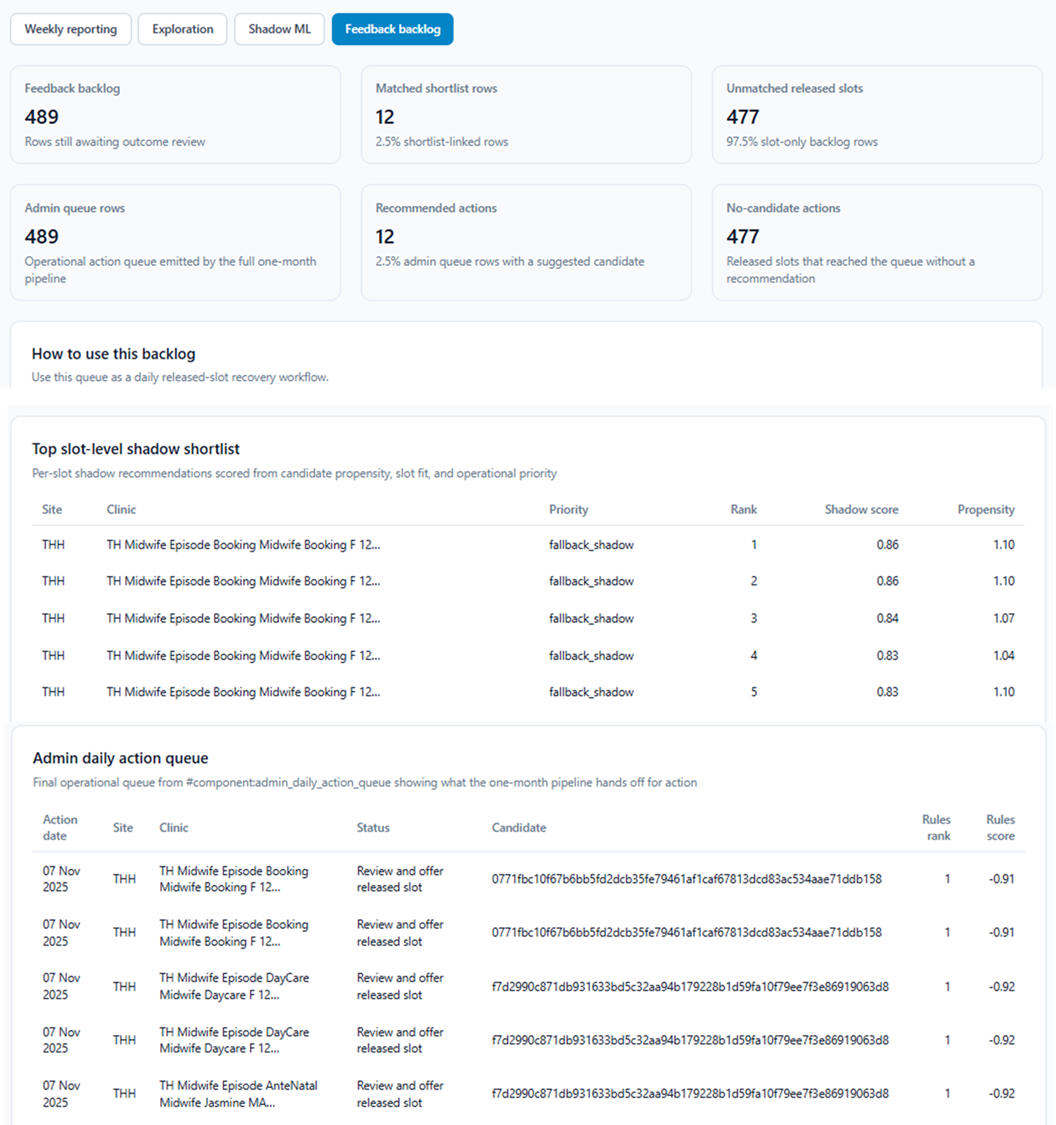
Dr. Tahmina Zebin, from Brunel University of London, built a 17-component pipeline on a real anonymized outpatient dataset that treats missed appointment capacity as something to be recovered, not just measured.
The pipeline identifies released slots from cancellations and reschedules in short-notice windows, builds patient-level operational features (prior DNA ["Did Not Attend"] behavior, cancellation history, referral priority, lead times), and generates a ranked shortlist of candidates to fill each recovered slot.
The most technically distinctive element: a shadow ML shortlist path that runs alongside the existing rules-based approach. Rather than replacing clinical judgment, the system displays both rankings side by side — letting coordinators see where the ML path and the rules-based method agree, and where the ML path surfaces additional slot recovery opportunities. A feedback backlog and admin action queue then translate those rankings into a usable clinical workflow.
Human-in-the-loop design wasn't a compromise here — it was intentional. The system is explicitly a triage and prioritization tool, not an automated booking engine.
What makes it stand out
This project takes a genuinely novel framing — missed appointment capacity as an operational recovery problem — and executes it with real-world outpatient appointment data, sophisticated dual-path ML architecture, and production-grade workflow thinking. The feedback backlog is a first-class output, not an afterthought.
"This project showed that missed appointment capacity can be treated as a recoverable operational problem, not just a reporting issue. Using Ascend and Otto, I was able to move from raw appointment data to a practical, clinic-facing workflow much faster than I could have done manually."
— Dr. Tahmina Zebin, Brunel University of London
Third Place: Subashini Subbaiah
Behavioral Health Intelligence Platform
The build
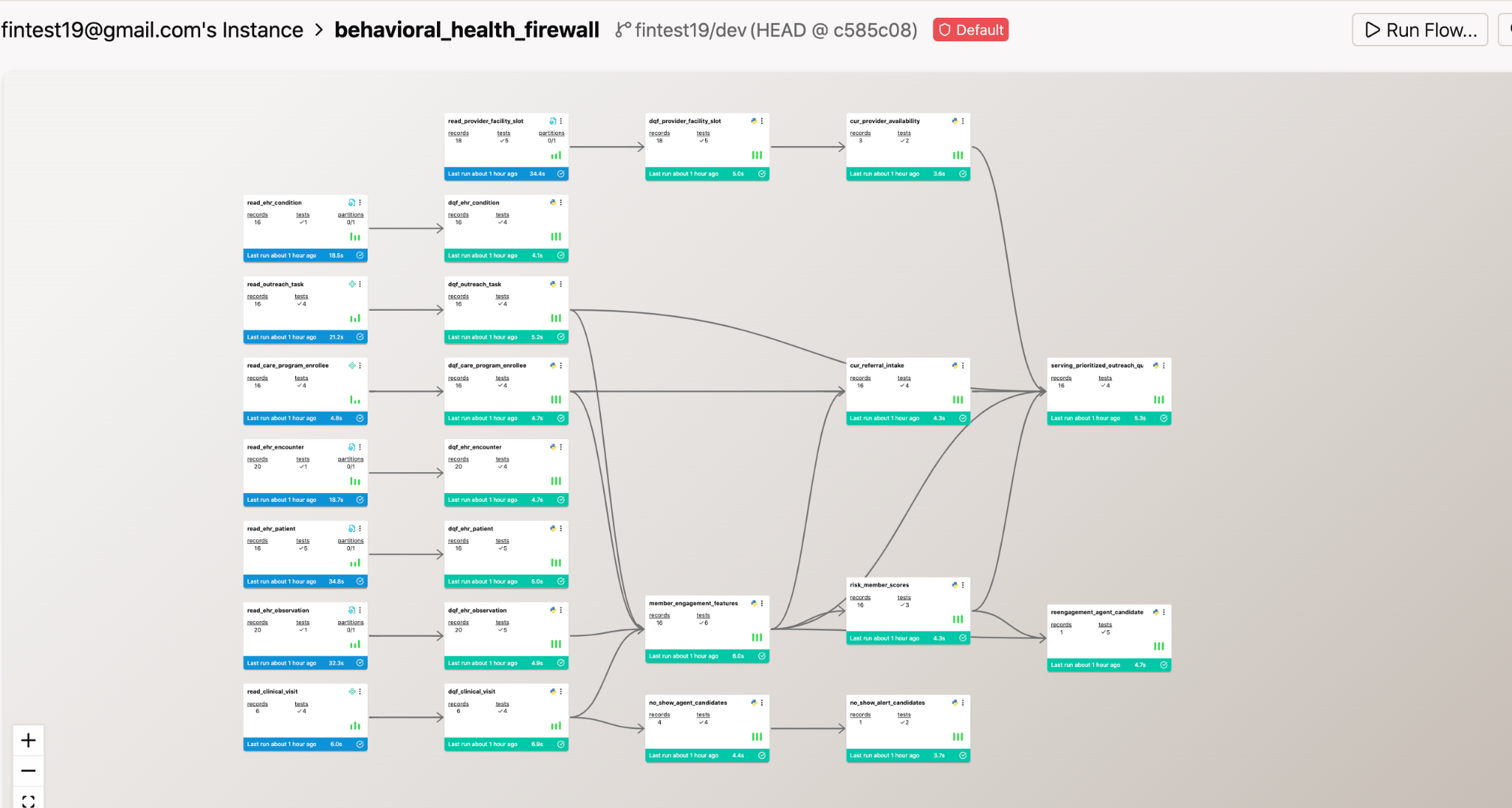
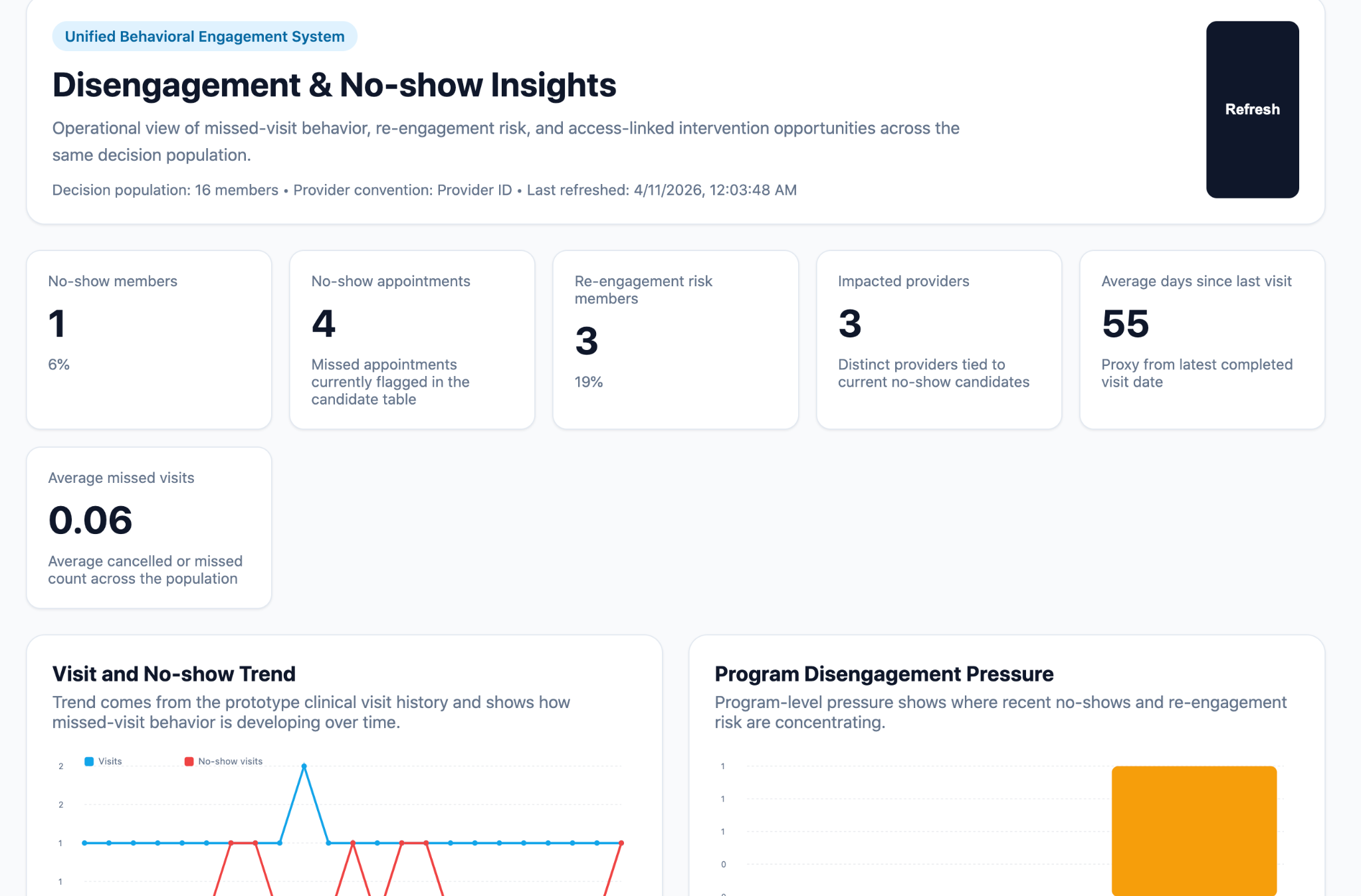
Subashini built a 24-component pipeline — one of the most complex in the cohort — that ingests behavioral health operational and clinical data, runs it through a dedicated Data Quality Firewall stage, builds member-level engagement and risk features, scores risk, and surfaces a prioritized intervention queue for care teams.
The system runs on a 30-minute refresh cycle. When the pipeline completes, AI agents automatically review outcomes and apply explicit decision logic: members flagged as high-risk with more than 30 days since last visit and fewer than 2 prior outreach attempts get surfaced for re-engagement. No-show candidates are queued for follow-up within 24 hours. Failure emails include Otto-generated root cause analysis instead of raw system errors.
The dashboard turns disengagement signals into an operational view: which members need intervention most, which programs have the highest no-show pressure, and what the recommended action is for each flagged member.
What makes it stand out
The Data Quality Firewall as a dedicated architecture stage — standardizing, validating, and deduplicating before any feature engineering begins — is serious production engineering. The explicit decision logic baked into the agents, combined with automated alerting and a 30-minute refresh cycle, makes this a genuinely always-on system, not a dashboard that someone has to remember to check.
"Shifted from performing analysis to building intelligent, always-on systems that connect data, insights, and actionable decisions."
— Subashini Subbaiah, Tech for Impact
Honorable Mentions: 10 more projects that blew us away
The top three weren't the only impressive work. Across the hackathon, builders tackled problems spanning clinical research operations, agriculture, social media analytics, DevOps observability, fraud detection, Ethereum forecasting, reinforcement learning research, and sustainable development. Here are ten more pipelines built in a week.
Maya Ospina — YouTube Monetization Intelligence Dashboard
Maya set out to build the foundation for an autonomous agent that could eventually identify and act on monetization opportunities from viral social media posting. The hackathon project was the first step: a comprehensive monetization intelligence dashboard powered by real YouTube data.
The build is an extraordinary engineering achievement with a 52-component pipeline, 9 transformation layers, 5 custom Otto rules, 3 automated workflows, and 3 datasources: a 5-million-row dataset spanning 113 countries stored in MotherDuck, the YouTube Data API, and Google Trends connected autonomously by Otto via pytrends. When Otto accidentally deleted all dashboard sections mid-build, git history saved the project, proving effective guardrails are key to agentic development.
Key findings from the dashboard: Flash content (fast rise, fast fall) earns nearly as much as Evergreen content (stays trending 9+ days) despite burning out faster, and the average published-to-trending time is approximately 115 hours.
"Git history is your safety net. Every change is recoverable if you can find the right commit."
— Maya Ospina



Mamta Venugopal — Agentic Refrigeration Diagnostic App
Mamta built a chat-style support application that combines large manual ingestion, retrieval-augmented generation, and operational automation into a single customer experience — designed to reduce unnecessary technician dispatches by 50% within six months. The scenario uses open-sourced Samsung product data and materials (public manuals and related sources).
The system's two intelligence layers — an Orchestrator Agent that maintains conversation state and decides next actions, and a Knowledge Retrieval Agent that searches manuals, FAQs, and service logs for model-specific evidence — produce grounded, citation-backed answers rather than generic troubleshooting text.
A second flow monitors the ingestion pipeline daily and sends Otto-generated failure alerts with root cause analysis and suggested next steps if anything breaks.
"If the goal is to meaningfully improve support outcomes like FCR and CSAT, a simple chatbot is not enough. You need an agentic system that can retrieve evidence, reason through it, and support both customer interaction and internal operations — and this project demonstrates exactly that."
— Mamta Venugopal, Ex-BSH

Leslie Paas — Brazilian SDG Accelerator for Local-Level Government Planners
Leslie built a municipality-level diagnostic and decision-support system to help local government planners in Brazil accelerate progress toward the 2030 Sustainable Development Goals — addressing the "knowledge-to-action gap" that leaves local administrators with access to data but no clear path to prioritized investment decisions.
The tool's core innovation is its Accelerator Logic: because the 17 SDGs are deeply interlinked, the system identifies interventions that address multiple low-scoring indicators simultaneously, directing limited municipal budgets toward the policies with the highest compound impact.
"I was stunned by Otto's agentic power to orchestrate diverse real-world datasets, generate complex calculations/visualizations, and architect scheduled monitoring systems—all at breathtaking speed. While human intelligence remains essential for envisioning solutions and directing meaningful impact, Otto proved the perfect implementer, limited only by my discovery process and the hackathon deadline."
— Leslie Paas

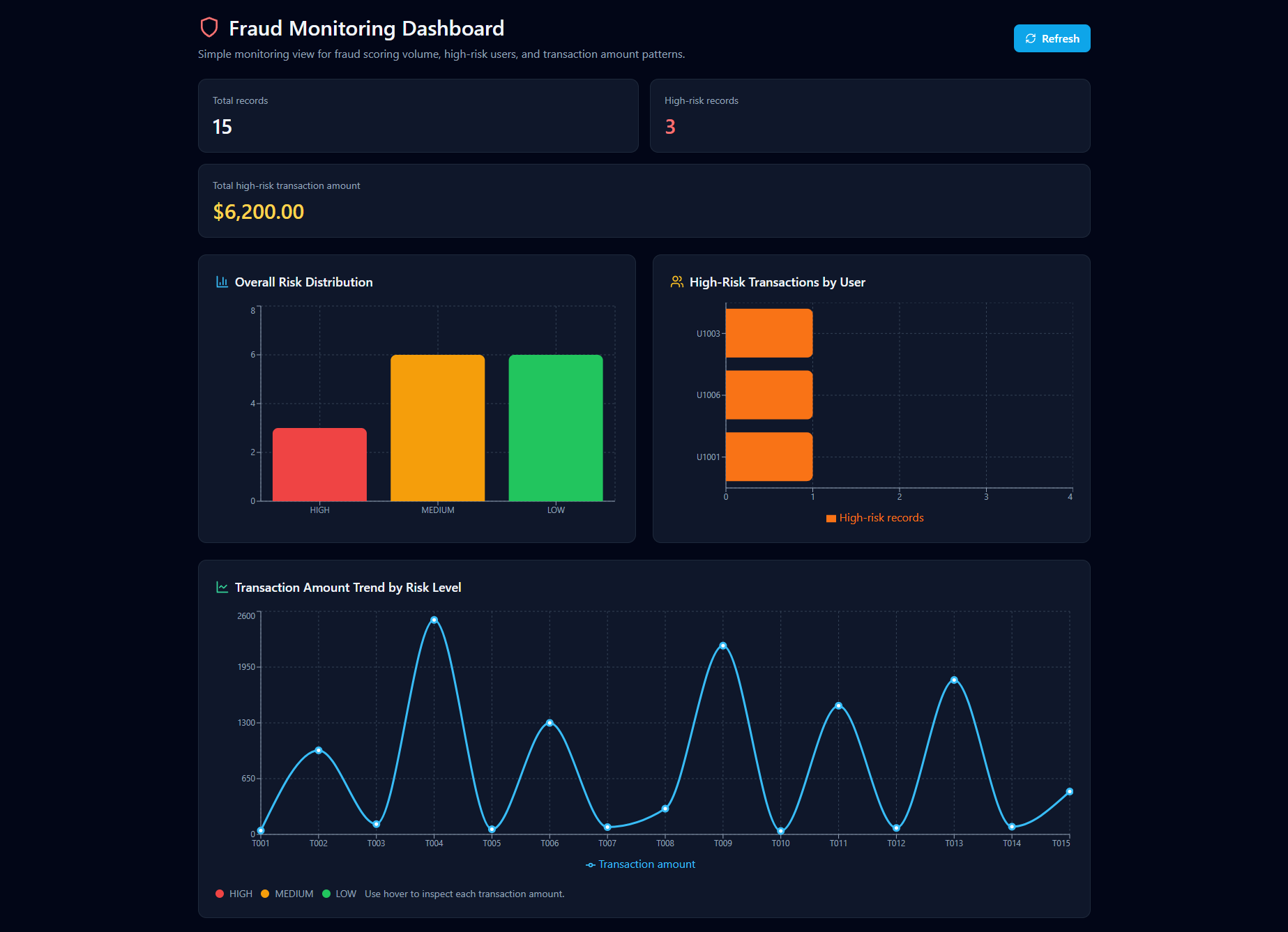
Portia Jefferson — FraudOps AI: Agentic Detection and Monitoring System
Portia built a proactive fraud detection pipeline for regulated financial environments — designed to continuously monitor, adapt, and respond to evolving risk patterns rather than relying on static rules or delayed batch processes.
The pipeline ingests transaction and message data, applies a combined risk scoring model (message signals + transaction signals → overall risk), triggers automated workflows for high-risk activity, and surfaces everything in a real-time monitoring dashboard. Custom Otto rules and hourly scheduled execution ensure the system is always running.
Indraneel Deodhar — Ethereum Price Forecasting
Indraneel built an Ethereum price forecasting pipeline with user-selectable forecast windows of 30, 60, 90, or 365 days, generating buy/sell signals based on predicted price trends and displaying results with a forecasted price corridor bounded by historical daily highs and lows.
"Talk to an agentic AI like you are talking to a person — the clearer the instructions, the better the result."
— Indraneel Deodhar

Hana Knill — Clinical Site Readiness Workflow
Hana built a two-flow agentic pipeline: an AI email classifier that captures incoming document metadata, identifies the likely site and document type, assigns a confidence score, and routes items to a human reviewer before anything updates; and a live readiness dashboard that recalculates site scores after review and surfaces next best actions — whether to escalate a stalled contract to a manager or send a targeted follow-up to a nearly-ready site missing one document.
In the live demo, the system tracked 11 sites, correctly classified documents from 5 incoming emails, and flagged 7 high-risk sites. Site 001 (40% readiness, incomplete contract) triggered an escalation recommendation. Site 103 (80% readiness, one missing delegation log) got a targeted follow-up prompt to push it into the enrollment phase.
"AI doesn't just accelerate individual tasks — it makes entire projects more ambitious and compresses the time from problem to working solution."
— Hana Knill

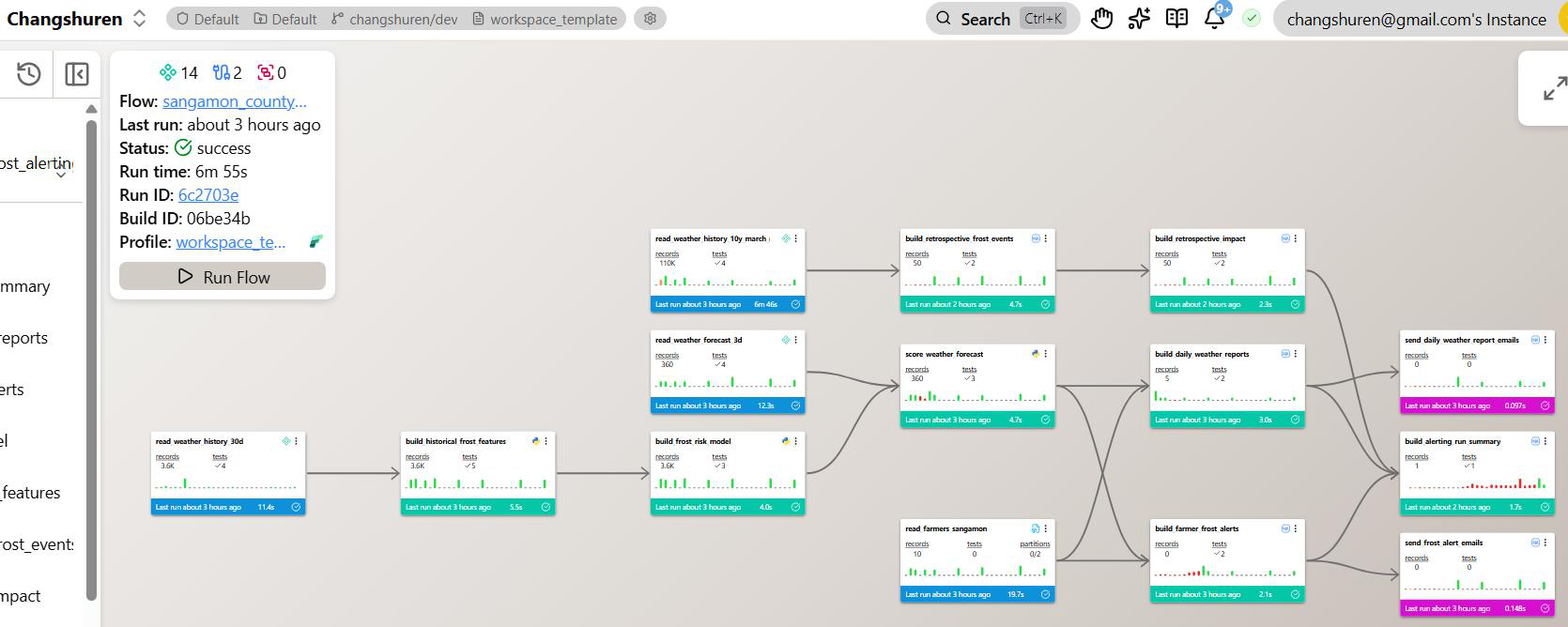
Shu-Ren Chang, Ph.D. — Early-Warning Frost Forecasting for Peach Growers
Shu-Ren built a 14-component production pipeline that forecasts frost risk for peach growers in Sangamon County, Illinois, up to three days in advance.
The system ingests live weather data from three Open-Meteo API streams — 30 days of hourly history, a 3-day hourly forecast, and 10 years of March-May historical data — trains an interpretable frost-risk model, scores upcoming forecast windows, and sends farmer-specific email alerts at 7 AM daily. A retrospective layer estimates how many frost events over the past decade could have been mitigated if this system had existed earlier.
The pipeline is fully scheduled, deployed on Ascend, and operationally self-monitoring with failure diagnostics and automated alerts.
"This project taught me how to design a resilient, production-grade data pipeline that combines real-time ingestion, machine learning, automated notifications, and retrospective analytics."
— Shu-Ren Chang, Ph.D.
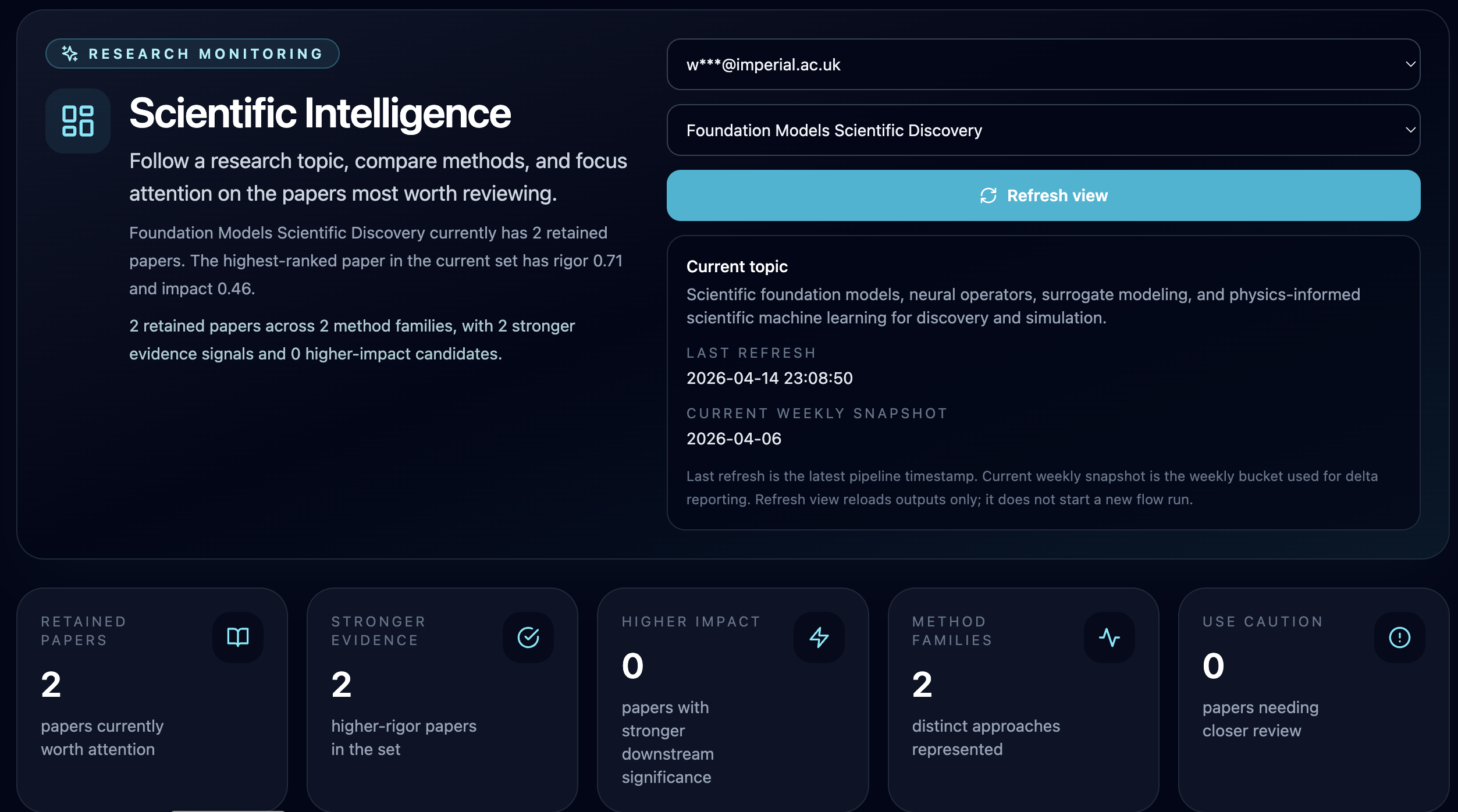
Wai Hoh Tang — Scientific Intelligence
Wai Hoh built an autonomous research monitoring system that helps researchers keep up with fast-moving fields without getting buried in paper overload. Unlike existing tools that stop at one-time summarization, it maintains weekly snapshots over time, tracking which papers are newly recommended, which have persisted from prior weeks, and which have dropped out. This turns a static list of papers into a live view of the research landscape.
The scoring system was deliberately designed to evaluate papers across independent dimensions: novelty, rigor, impact, evidence strength, and overclaim risk. This means the system can flag a paper as genuinely interesting while noting it may not yet be well-supported by evidence, rather than simply rewarding whichever abstract sounds most exciting.
"Fast summarization is easy to demo. Trustworthy monitoring is much harder, and much more valuable."
— Wai Hoh Tang, Imperial College London
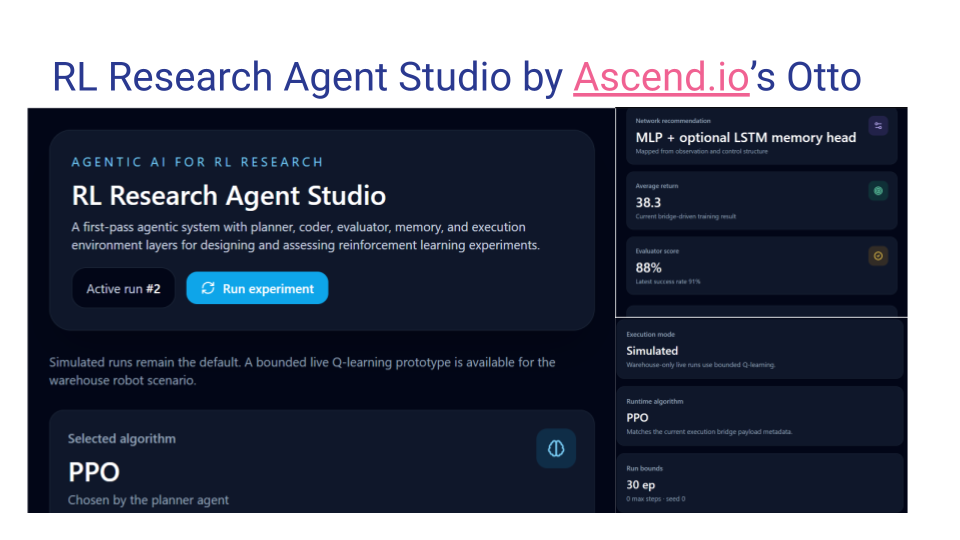
Krishnamurthy Venugopala Vemuru — RL Research Agent Studio
Krishnamurthy built a multi-agent research studio for reinforcement learning experimentation — using Otto, Otto Professor, Code Reviewer, and Planner agents in deliberate sequence, each playing a distinct role: designing the pipeline, reviewing it for research quality, planning development tasks, and auditing for security issues.
The studio takes a user-defined RL task, runs it through a planner → coder → execution environment → evaluator → memory loop, and produces reward curves, policy summaries, and a structured research narrative. A memory layer stores prior experiment knowledge so each run builds on what came before.
"By teaming with AI, and by using carefully designed safety principles, humans can accelerate technology development."
— Krishnamurthy Venugopala Vemuru, Ph.D.
John Georges — DevOps Incident Pipeline
John built a pipeline that analyzes GitHub Actions workflow-run telemetry to identify unstable services, repeated workflow failures, and high-risk operational patterns. The pipeline runs on a 7 AM daily schedule, with Otto-driven post-run summaries automatically generated for services that cross risk thresholds — so engineers know what needs attention before they start their day.

What These Projects Have in Common
Across healthcare, agriculture, fintech, climate science, and operational analytics, a few things showed up consistently in the strongest builds.
The agentic setup came before the pipeline. The top builders didn't jump straight into components. They spent time designing Otto rules, custom agents, and automation logic first — so every component built downstream inherited those constraints automatically. The rules library became more valuable than any individual pipeline piece.
Real data changes what's possible. Seven years of genuine Amazon reviews, anonymized outpatient appointment data, live Open-Meteo APIs, actual agricultural frost records — real data turned dashboards from demos into systems that tell true stories.
Human-in-the-loop is a feature, not a limitation. Multiple top projects deliberately kept humans in the decision loop — not because the AI couldn't automate further, but because the domain demanded it. Clinical research, healthcare operations, and slot recovery all require human validation before scores update or actions trigger. Building that constraint in from the start is what makes these systems trustworthy.
The role shifted from writing code to defining constraints. Watching Otto build a component, run it, spot a schema mismatch, fix it, and rerun autonomously changed how multiple builders described their work. The builder's job became defining what the system should accomplish and setting the guardrails — not writing the implementation. That's agentic data engineering in practice.
Build What's Next
Our hackathon participants went from idea to deployed pipeline in one week. What could you build with Ascend?
→ Automate customer support intelligence like Nidhi
→ Build operational slot recovery like Tahmina
→ Detect behavioral health risk like Subashini
→ Activate clinical trial sites faster like Hana
→ Forecast agricultural risk like Shu-Ren
→ Monitor research landscapes like Wai Hoh
→ Build fraud detection like Portia
Start your free trial at ascend.io and see what's possible when domain expertise meets agentic data engineering.
