For those who are already customers, you will know that customer delight is our #1 priority across the entire company—it's baked into the very basis of the Ascend DNA. From a product/engineering perspective, we've worked extremely hard to operationalize a weekly product delivery cadence that enables us to release features and fixes at an extreme velocity. In addition, immediate customer needs represent at least 60% of our product pipeline at any time frequently delivering capabilities within weeks of request.
From a customer support perspective, responding to and resolving any type of customer question is both the responsibility of everyone in the company and the primary consideration to our weekly "I Got It" award, the most coveted in the company.
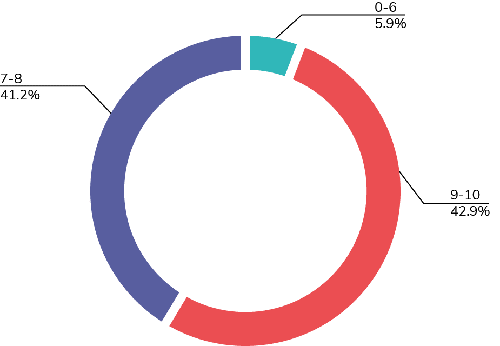
To help ensure we are executing to customer delight, we are engaging in a twice a year Net Promoter Score (NPS) survey to take the pulse of the hands-on users of our product. Below are the results of the survey completed this past July.

For those of you unfamiliar with the "grading" associated with NPS, scores of 9-10 are identified as "Promoters," 7-8 as "Neutral," and 0-6 as "Detractors." The "NPS Score" is calculated by taking the percentage of Promoters less the percentage of Detractors. And we are thrilled to have a NPS score of 47!
But what does that mean? Here are a couple of op-level takeaways:
- The most widely cited benchmark for B2B software is 30—though it can vary greatly based upon being a niche product (higher) vs. a broad enterprise platform (lower). Because of these variations, the best approach is to compete with yourself, so while our NPS score is quite a bit higher at 47, that becomes our own benchmark and we'll be looking to improve on this in our next survey to 55.
- We also have decided to target an average score to make sure that we are penalized more for lower scores. There is no benchmark for this that we have found, so we are using an incredibly aggressive target of 9.0 to ensure we are constantly looking to improve. To emphasize how difficult this is, one score of 5 requires 4 scores of 10. Our average for this survey was 8.1 so we have room for improvement.
Moving Forward:
So while these results validate our focus on customer delight is working, improvement is what it is all about. Thus part of the survey was also asking more qualitative questions of our customers to understand where we're succeeding and where we can improve. The themes we heard from the survey that we will be working on in the next 6 months include:
- Continue the great feature velocity!
- UI-based source control
- Native Great Expectations integration
- Even more native connectors for data ingest
- Next-level observability
- Improve overall stability
These themes are all embedded in our product roadmap for the next 3 months as we look to drive even more customer delight!

{kind=link}