.webp)




.webp)

.webp)



.webp)


With the recent consolidation in the area of Modern Data Stack, the question arises: are open data stacks, a more flexible but labor-intensive way of building data platforms, out of fashion? Are we transitioning into an era where we use unified data platforms that do end-to-end analytics and are integrated with metadata and control plane?
Data platforms that make automatic choices provide a fully functional data platform where you can get started with analytics immediately. They give you all the batteries included. No setting up weeks of CI/CD pipelines, Kubernetes clusters, and different environments. Best of all, they eliminate the hard questions of where to put my business logic, where do I run my compute (which engine do I use), what are the best tools for transformations. All of these have been answered in a verified and unified way. The solution is an opinionated data platform.
Depending on your preferences, an opinionated data platform might have all you need, and you get analytics with a single unified tool. No contract discussions with multiple vendors, talking to major sales teams just to get started. Just sign up, and start doing analytics.
This article is a deep dive comparing open data platforms and their tools with a closed-source platform approach. We check what the differences are and see when to use which. We talk about the connecting thread such as open standards, pros and cons, current market, and much more.
What Does Opinionated Data Platform Mean?
What does opinionated actually mean? In the context of a data stack, it means that the tools and setup for the best deployment to provide an end-to-end analytics solution have been made for you.
Think of it like Omakase, a chef's choice:
Omakase is a Japanese phrase, used when ordering food in restaurants, that means "I'll leave it up to you".
Just like a chef choosing the best ingredients for their menu, you leave it up to the data engineers (and team), the ones who built an all-cohesive data platform. Opinionated also because the data engineers and architects made some hard choices that limit you in some areas and set you free from the process of choosing the never-ending latest tools, which can be fun and all, but also takes hard work if you want to compare them seriously or integrate different tools into a common interface. Almost always you'd need to build or create some sort of web UI. However, even harder is making it into something that is maintainable over the long run by your team.
Without spending all waking hours on the setup and fixing bugs, you can actually add value to the business with new insights or reports that can help the company navigate difficult times or decide where to invest money and focus.
It means that the provider has beliefs about the data stack in a certain way, and all its software is crafted around this approach. The same way that you leave it up to the chef in an Omakase restaurant.
You can still add custom logic needed for your organization, but within a setup that has been tested and proven.
Modern Data Stack vs. Opinionated Data Stack
Hard opinions and especially an integration into a data platform often mean it is a closed system, because logs, metadata, and security need to be unified and integrated across the platform. Therefore, it makes sense to do it once, in a unified way.
Therefore, the opposite of an opinionated data stack that has end-to-end integration is a modern data stack, or any Open Data Stack. In contrast, with an open stack, you and your team get to be the chef and choose which tool you use, how to integrate, how it gets deployed on the server, and which underlying storage format to use.
In an opinionated setup, this has all been chosen for you. It's like building a house from scratch, choosing all the knobs, the light switches, every little detail yourself, versus an opinionated data stack that comes fully furnished and functional.
Current Market Trends
Recently, the market is consolidating among bigger players such as Databricks, Snowflake, and most recently Fivetran, which merged with dbt. Maybe you asked yourself what these mergers mean, what does the Fivetran + dbt merger mean, and is it the rise of closed platforms?
The choices today are mostly between a fully integrated data platform that Fivetran wants to build with Census, dbt, and previously MetricFlow, a closed and payable cloud solution, or building one yourself based on open-source data tech. However, you could also build a hybrid. The variations are mostly endless. And on top of that, if you are a larger organization, you most certainly already have both an integrated end-to-end platform in place and several teams that optimize specific use cases with dedicated open-source tools.
But the choices with the Fivetran acquisition and other market analysis point more and more back to bundling where bigger companies provide end-to-end data solutions from one vendor. Having this unified, opinionated data platform also means less complexity and fewer vendors involved.
I still see many good open-source software (OSS) tools, and don't see that changing just because dbt was acquired. The dbt-core is basically a templating framework for SQL. There are many other options for that too that are still OSS.
Luckily, there is an interesting link between the two that both are benefiting from, called open standards, which makes sharing and collaboration between the two possible without interruption or hard interfaces, and makes the choice a little less daunting.
A quick excursion to recent Acquisitions
If we have a look at the recent history and acquisitions, we can see that unification is happening in the open data stack, which might be an indication of opinionated data platforms growing:
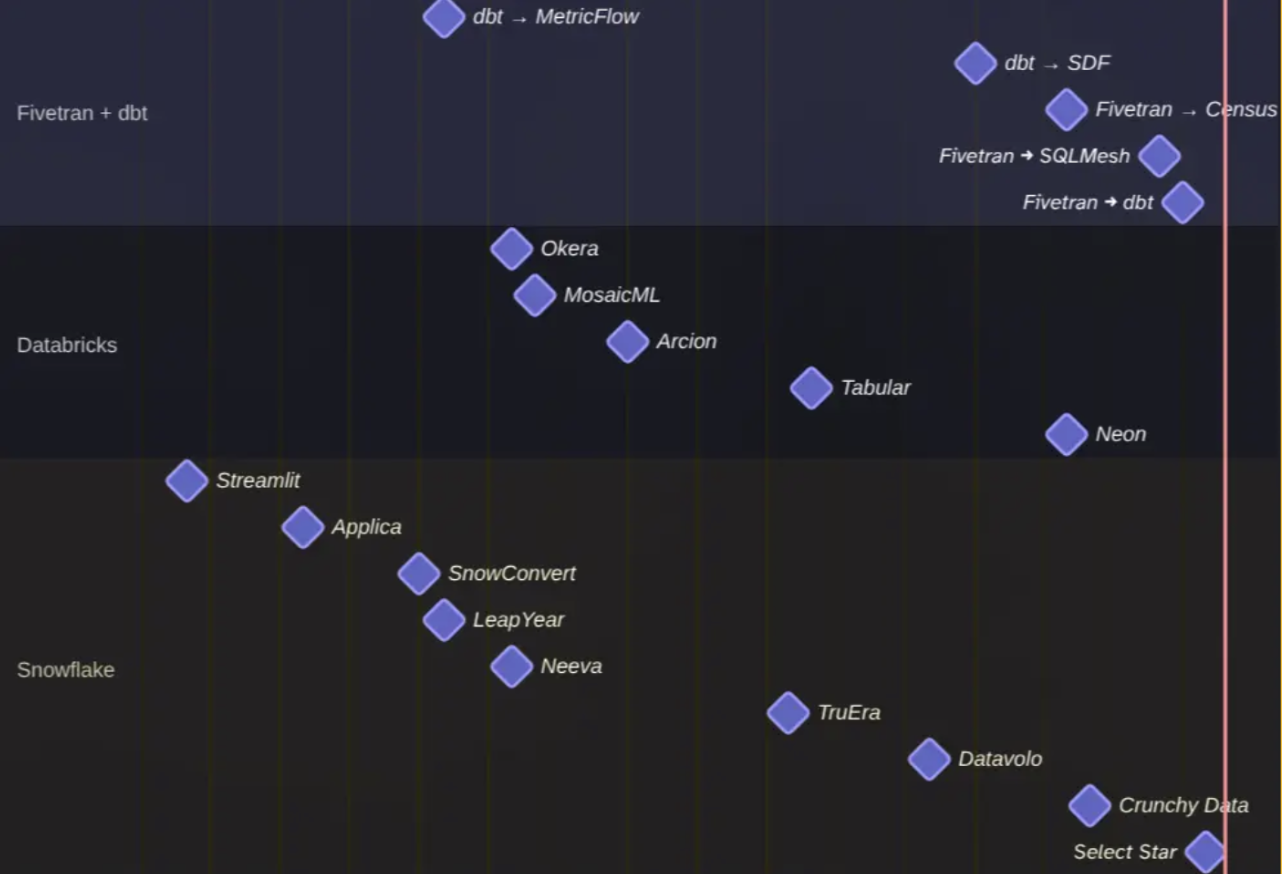
See the full picture on the trend of consolidations at Data Engineering Acquisitions, but also note that consolidating the Modern Data Stack is not over.
Closed vs. Open Data Platform
Before we get to open standards and what they mean, let's explore more about what open-source and an opinionated data stack mean. What are the differences, what are the advantages of an open data stack, and when is the opinionated but proprietary stack a better choice?
The hidden costs of fragmented (or also called unbundled) modern data stacks: spending time on engineering the platform, longer onboarding, debugging across multiple non-integrated tools, and hard-to-upgrade tools as each has individual patch releases.
There are still many reasons for using open-source software. However, when you need a platform, not a "tool", fast without much effort, open-source is not the right choice.
I see open-source and building an open data stack on top of it as a little like the (Linux) philosophy where each tool does one thing very well. Combined, you have a strong toolbox with different toolsets for each use case. Larger integrated platforms that just work with no maintenance on your end are when closed-source platforms make more sense.
A Comparison: Build vs. Buy
Another way of looking at closed vs. open-source data platforms can be "build vs. buy". A comparison of pros and cons of an open-source platform and an opinionated data platform is shown below.
In summary, choose open source when you have technical expertise and need maximum flexibility. Choose opinionated closed source when you need to deliver analytics quickly without the skills and the maintenance overhead of managing a complex multi-tool stack.
The best closed-source platforms are those built on open standards, providing the ability to use your data with other engines or platforms or integrate in different ways. Especially in larger organizations, you usually do not have only a single data solution.
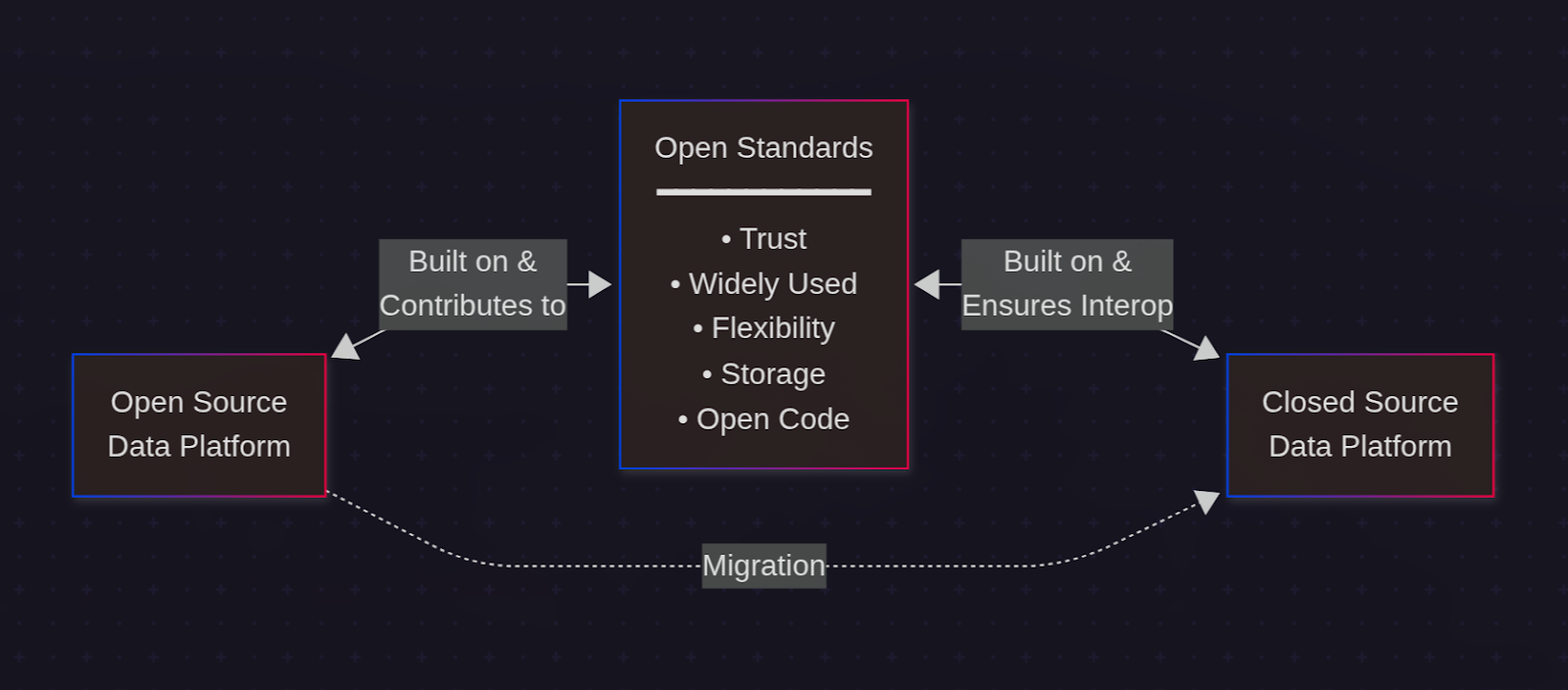
The Foundation of Both Is «Open Standards»
The link between the two is open standards. With them in place, we can interchange parts of the stack and use both, or migrate from one to the other.
Openness and building a data platform on open standards matter as much as just being open-source. We can use free open-source tools and build a data stack that creates proprietary data sets. Or we can use an opinionated data platform that is closed-source but that reads and writes data sets built on open standards.
Building on open standards is the best approach, even more so for data than for software. Why? Because data is the most valuable part of a company, and if we lose it, most companies lose their edge and, frankly, their reason to be around, no matter what industry they're in.
If a tool needs to change or has no new patches anymore but the data is in Parquet, we can just go ahead and read it with any other data tool immediately. We'd need to re-implement business logic, though. But if we use SQL or Python, this is transferable as well.
Building on openness with open standards is a bet on sustainability and gives you trust and visibility in return. Good examples are using Apache Spark, Open Table Formats such as Iceberg or Delta Lake, or Apache Arrow. By using and investing in these, we also collaborate globally, and we get better tooling and integration for everyone.
In the end, openness and standards help us avoid silos, something that was very common in the early days of data, where data was stored away in proprietary database formats and you could only read it with proprietary software.
Open Standards in More Detail
Most important, and more than the code, is the data itself. Data is the key to a company. If we are able to store it in a standard, we can also allow sharing without duplicating all the data or an expensive data migration. Below we see the difference in features between the two and their overlap, mostly in the infrastructure, storage formats, and the way they can use the same data, e.g., when stored on S3 in Iceberg.

Open-source optimizes for new innovations, customization, and avoiding vendor lock-in with the constraint to the skills and people who know about the stack and tooling in detail, or have time to learn.
Closed-source optimizes for operational simplicity, time-to-value, and reduced maintenance and fast battle-tested workflows. You pay a fee but don't have to maintain or invest knowledge-setup time for infrastructure, and can focus immediately on building value.
Examples of Open Standards
The best examples are happening currently, where all the major data platforms build their storage around Open Table Formats such as Apache Iceberg, Delta Lake, or Hudi. Other examples include using Terraform or Kubernetes which got to be open standards to deploy infrastructure. Or the new initiative like the Open Semantic Interchange (OSI) that wants to standardize a vendor-agnostic specification for describing semantic models, so that every open and closed-source platform can build their tooling based on it.
Apache Arrow, an interoperable data format, is another great example that allows you to avoid constantly converting from one format or dataframe to another, saving costly transformation and serialization compute cost.

An example that can be seen with an open format such as Apache Arrow on the top, or without on the bottom.
We can summarize the differences and the benefits of open standards and can say that without open standards, each system uses different formats and the cost of conversion when you want to integrate a new tool can be high. Storing the data multiple times in different formats (CSVs, Database, Data Lake) vs. having one format with shared functionality is inefficient and needs more complex integration compared to seamless interoperability with open formats.
Ultimately, open standards help in avoiding siloed data or heavy and complex integration overhead.
The Advantages of an Opinionated Data Stack
The most significant advantage is the amount of work you save with DevOps. Everyone who has started out to build their data stack, let alone a full platform, knows how hard and how much effort and knowledge it takes to deploy with proper tests, CI/CD, and automation with a git-ops-style chain.
Integrating all parts of the data stack into a unified platform and serving it as a reliable service is extremely hard. I'd argue that this is the biggest and hardest task of a data engineer today if you are focused on infrastructure or automating things as opposed to being business or analytics-focused.
DevOps is the Hardest Part to Get Right
On the other hand, opinionated data platforms just work out of the box. Such a data platform offers that interface for creating data platforms. Infrastructure as Code (IaC) with Kubernetes, versioned, with data migration in mind, all in a scalable way, is no piece of cake and shouldn't be underestimated.
To me, DevOps is the new data engineering of data science, just as a decade ago "when we did data science, we essentially ended up spending 80% of our time on data engineering".
Choosing an open-source tool, using it locally, and doing advanced analytics is the easy part, and where most people also get the value from. But deploying it for the entire company at a scale that just works in a scalable and reliable way is really difficult. It's even harder if you need to integrate with other existing services and tools in your company.
Another critical, but often neglected organizational piece, is separation of concerns. "Where do you deploy data pipelines?" or "Where is the logic of your business, and where do you put the infrastructure configurations such as RAM, CPUs?" These are not easy questions and are hard to separate in a meaningful way, especially to get it right on the first try.
Opinionated data stacks have all these questions answered for you, so you don't have to figure it all out. They have dealt with it long enough for many customers, which means it's implemented in an intelligent way, usually something along the lines of data engineering workspaces, separating infra from business logic and data pipelines.
Flexibility vs. No-Code
On top of that, opinionated data platforms provide no-code interfaces that help everyone, including less technical people, to get off the ground immediately.
Brooklyn Data says about that flexibility matters more than ever. Something you can get mostly from an OSS data stack, but also if you have an opinionated data platform that lets you run Python or SQL.
That brings us to the question "what is needed for a great data platform that gets you the right analytical questions answered?".
I'd say the first thing is that the platform gets out of your way and just lets you insert and ingest data and lets you get analytics out in minutes. No need to install or spend hours setting things up or spending time on DevOps practices or complex CI/CD pipelines.
Some of the key ingredients are:
- low effort and immediately able to start
- end-to-end analytics to profit from integration and declarative DevOps (so as to have lineage and metadata, deployment, all integrated)
- integrated with the open standards of the data ecosystem so you don't have major breaks at every interface
- native observability and monitoring to catch errors early and debug across the entire pipeline without tool-hopping
- separation of business logic from infrastructure concerns, allowing technical and non-technical team members to collaborate effectively
- strong compute that can scale out to as large as your data needs it to be
We can say it must serve every part of the DataOps lifecycle.
DataOps
What does that mean? DataOps usually means that every part of the data flow, from ingestion to how the team works with it to the automation, is thought through. That it's easy to build, develop, plan, and deploy new data artefacts and get valuable insights out of it with automated monitoring, environment management, and tests.
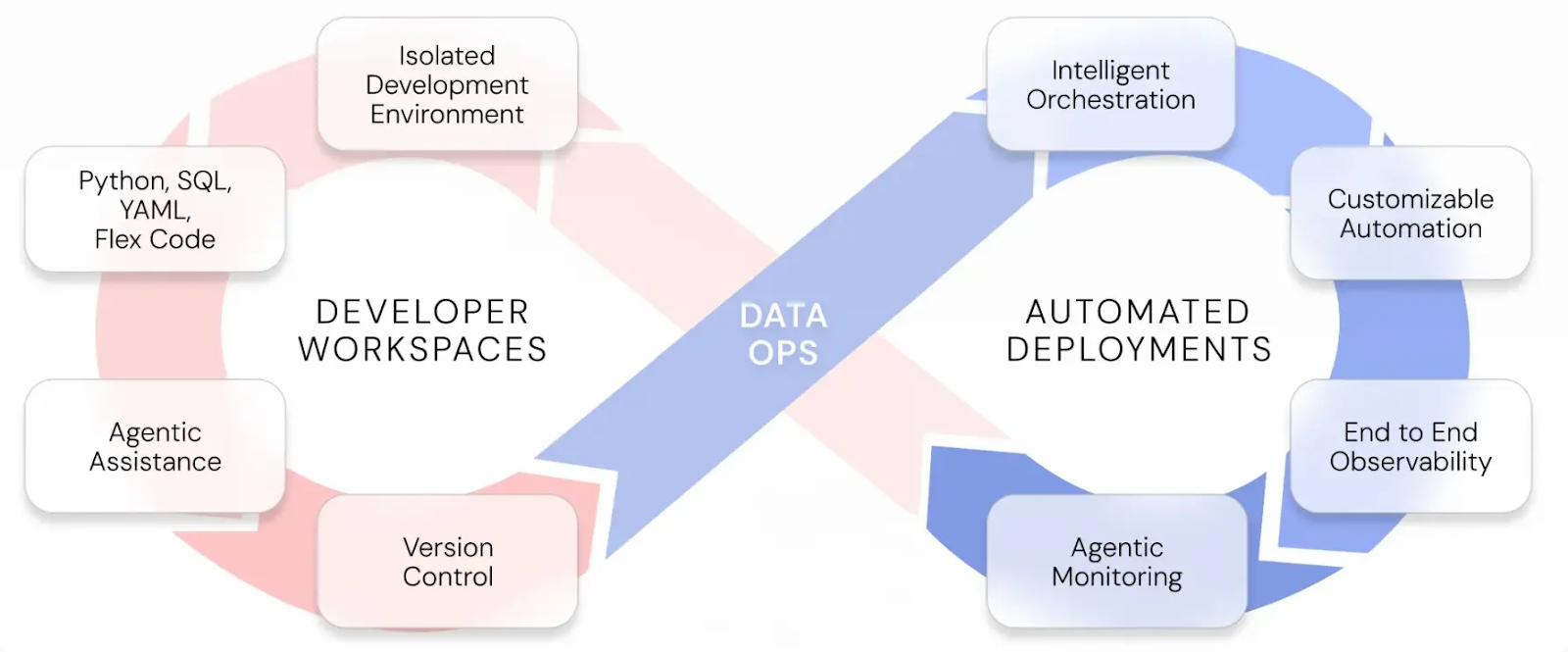
If done right, developer velocity with automatic deployments will increase and developing new features becomes more fluid. The ability to separate business logic from technical implementation with dedicated workspaces that can have different code artefacts, such as dbt-SQL in one and Python code in another, is a big benefit. As different teams use different tools and different languages, it's important to support the teams where they are.
Even more so if there's an assistant that knows all the metadata and understands the context of your business like an AI agent trained and ingested with the platform's logs and settings. This works best when the platform embraces a declarative, configuration-driven setup. In these environments, people can collaborate with AI agents in a regulated way, as configurations can be seen and verified by users when an assistant is generating a new transformation.
Traditional DataOps without an integrated data platform is not enough, as it has:
- too many tools, manual workflows, and knowledge about the tools that is not well distributed
- low visibility and is hard to debug
- slow incident response time for creating new features for the business
- high engineering and maintenance burden
Ultimately, DataOps is the right set of principles in place for your data system that always improves quality and agility across the full data lifecycle. It incorporates everything shown in the above illustration such as automation, testing, CI/CD, monitoring, and a way to resolve incidents in a fast and safe manner.
Don't Just Orchestrate. Automate.
This is where Ascend comes into play, an opinionated data platform that answers most of what we've discussed in this article so far about an opinionated data platform. No manual orchestration with Airflow or scattered cron jobs. Ascend automates intelligently, dynamically building DAGs based on data dependencies through a clean UI. It's fully data-aware and declarative, spawning executors automatically and scaling to your needs. Through this unified approach, you get end-to-end lineage with built-in sensors and triggers that react to data changes or schedules.
But Ascend extends beyond smart orchestration. It separates developer workspaces from deployment environments, solving the "separation of concerns" problem. You develop and test in git-branched workspaces alongside AI agents called Otto, while deployments remain read-only for reviewed code only. Business logic lives in Python or SQL. Infrastructure concerns stay in the deployment layer. This clean architecture enables agentic data engineering. Otto has access to all platform metadata, logs, git history, and lineage. When pipelines fail, Otto explains what happened, suggests fixes, and can implement them in your workspace for review.
The architecture solves our core tensions: flexibility to write Python or SQL, plus the integration of a unified platform handling ingestion, transformation, orchestration, and observability natively. You can skip DevOps work as the git workflows and monitoring come included. Ascend works with open table formats and standard SQL/Python, making hard architectural decisions for you while leaving business logic, data, and customization entirely in your control.
Wrapping Up and Conclusion
As you've seen, with an opinionated data platform, you can avoid worrying if the data pipeline breaks because of a misconfigured infra setting or a container went stale. Data pipelines break less often because they are built in a rigid and well-set-up structure. Because the monitoring system is extremely strong, you don't have silent errors that only appear in a week or a month and are very hard to recover from.
The math is simple. Time spent integrating tools is time not spent delivering value.
Ascend, a fully functional and opinionated data platform with everything your manager or you as an engineer wish for, is integrated natively.
- 100s of ingestions and connectors? Native.
- Transformation? Native.
- Orchestration? Native.
- Observability? Native.
- AI assistance? Native.
Avoiding traditional duct taping. No sudden breaking changes. No long integration projects for new features. These come out of the box.
If any of these sound interesting to you, start a trial and check Ascend for yourself, or read more in the docs. Stay tuned for Part 2, where we'll explore the unique features and the unified data platform feature in more detail.



.avif)
