.webp)




.webp)

.webp)



.webp)


You know the feeling. It's Monday morning and a pipeline is broken… again. Your team is doing rock-paper-scissors to see who has to touch it. The one person who understands the logic is on PTO. And your stakeholders are already Slacking you asking why the dashboard is out of date.
If this sounds painfully familiar, you're dealing with tech debt. And you're far from alone.
According to our annual DataAware Pulse Survey, 50% of all data engineering time goes to maintaining pipelines, rather than building new data sets to fuel their organizations. And research from Monte Carlo has found that data professionals spend roughly 40% of their time just evaluating or checking data quality.
That's an enormous amount of capacity locked up in reactive work instead of building new data products that actually move the business forward.
The good news? There's a clear path out — and it's faster than you might think, especially if you bring AI agents into the process.
If you are wasting valuable time, money, and energy on tech debt, Here's the playbook to start reducing it and preventing future problems.
Step 1: Audit Your Tech Debt
Before you can fix anything, you need to understand what you're dealing with. I break the audit into two parts: qualitative insights from your team and quantitative signals from your systems.
Talk to your engineers first
Ask them four questions:
- What pipelines are scary to touch? The ones where it's "nose goes" to see who has to deal with it.
- What requires manual intervention? Those little tweaks someone has to make weekly or monthly.
- Where do you rely on tribal knowledge? What systems require calling one specific person every time something goes wrong? (This is a business continuity risk — not just a time sink.)
- Where do upstream changes frequently break us? Schema changes from third-party sources or internal teams that nobody told you about.
Your team already knows where the biggest pain points live. You don't need a perfect, comprehensive catalog — perfection is the enemy of progress here. Start with the pipelines generating the most incidents and complaints.
(It’s also worth noting: once you move to an agentic approach in Steps 3 and 4, your agents can help surface these signals continuously, but the human insight from your team is a good place to start.)
Then pull the quantitative signals
Look across three dimensions:
- Pipeline health — Failure and retry rates, SLA misses, late data delivery, long-running or frequently backfilled jobs.
- Data quality — How many tables lack tests? Where are you seeing schema drift and how much time is your team spending to address it? Where are there freshness issues or manual validation steps before data can be trusted?
- Platform — What's the cost trajectory of your legacy tools? (I recently spoke with a team whose legacy platform was charging them 9x year-over-year — sometimes your tech debt is just your tooling costs.) What's your CI/CD maturity? How complex is your orchestration? Do you have dependency sprawl across disconnected systems?
Categorize by root cause
This is where the audit becomes truly actionable. Surfacing issues is important, but it's not enough. You need to understand why things are breaking so you can target the root cause, not just the symptoms. I see teams skip this step and jump straight to fixing individual pipelines, only to find the same problems resurfacing weeks later because the underlying issue was never addressed.
Group your findings into five categories:
- Architecture debt — Are you tightly coupled to a legacy platform? Are you using a patchwork of disconnected tools for ingestion, transformation, and orchestration with no real visibility across them? If you trigger a flow, do you know what happens downstream?
Architecture debt often shows up as that general feeling of "we can't see what's actually happening in our system." When your tools are spread across multiple platforms with no unified lineage, data arriving late in one system means transformations in another have already run — and you may never even know.
- Data quality gaps — This one is often the most straightforward to quantify. What percentage of your tables have no data quality tests at all? Where do you have schema drift that nobody's monitoring? Where are engineers manually validating output before it goes to stakeholders? If the answer to "do we have data quality checks in place?" is "not really" — well, at least you know where you stand. And honestly, that makes the path forward pretty clear.
- Orchestration fragility — Are there fragile dependencies across your system? Can you see end-to-end orchestration across flows, or are you dealing with a tangled web of triggers and schedules that nobody fully understands? Fragile orchestration is what turns a minor upstream delay into a cascade of downstream failures.
- Dependency or version drift — This covers both external source system dependencies (third-party APIs that change schemas without warning) and internal version drift in your codebase. If you're constantly firefighting because a source system changed something, that's a dependency problem that needs a systemic solution — not just a one-off fix every time it happens. (This is actually one of the areas where Smart Schema Management can eliminate an entire category of pain.)
- Documentation and ownership gaps — These are the pipelines that rely on tribal knowledge to deploy and debug. If one person leaves or goes on vacation and suddenly nobody understands how a critical system works, that's a documentation and ownership problem. It's also a major risk multiplier for every other category — architecture debt is harder to resolve when nobody documented the architecture, and data quality issues take longer to fix when there's no lineage documentation to trace.
The reason this categorization matters is that it changes what you prioritize. If most of your tech debt traces back to architecture issues, fixing individual pipelines one at a time won't get you very far — you need a platform-level solution. If it's mostly documentation and ownership gaps, the fix is different (and, as I'll cover in Step 4, something agents can largely automate). Root cause categorization is what turns "we have tech debt" into "here's the specific plan to address it."
Step 2: Make the Business Case
This is where a lot of data teams get stuck. Tech debt work can feel like "maintenance" to the business — not exciting, not new capability. The key is translating your findings into language stakeholders care about.

Score each debt item across four dimensions
That last one — trust — is often the most damaging and the hardest to recover from. When an executive says "this data is wrong," that's a nightmare for every data team. And the downstream effects ripple: analysts start pulling raw data and writing unoptimized SQL just to verify their numbers, creating even more duplicate work.
Present a plan with timelines
The business wants to know three things: how much you'll save them, how much more you'll be able to deliver, and what you'll do to prevent this from happening again. Give them concrete numbers from your audit, measurable outcomes (like reducing incidents by X% or lowering failure rates), and — critically — timelines. If you can show that three to four weeks of focused effort will unlock significantly more productivity over the next year, that's a compelling case.
One thing I'd emphasize: include your prevention plan in the pitch. Executives don't want to fund a tech debt cleanup that they'll have to fund again in two years. When you can show that you're not just fixing things but putting agentic systems in place to enforce standards going forward, that changes the conversation from "maintenance expense" to "strategic investment."
Step 3: Reduce Existing Debt
With buy-in secured, the actual resolution work falls into four areas:
- Platform modernization — If your audit revealed architecture debt or spiraling platform costs, this is where you address it. The goal is reducing the dependency sprawl and blind spots that are generating tech debt in the first place.
- Simplification and deduplication — This is one of the highest-ROI areas I see. Over time, codebases accumulate redundant logic — engineers building pipelines that essentially already exist because they didn't know about them, or creating slight variations of the same transformation because it was faster than finding and modifying the original.
Templates and macros are your best friends here. When you standardize common patterns into reusable templates, you're not just cleaning up today's code — you're making it structurally harder for duplication to creep back in. - Code optimization — This is about making what you have run better. Which pipelines are long-running? Where are the bottlenecks? Are there queries that could be restructured to cut compute costs significantly? Optimization work often has an outsized impact on your cloud spend, and the improvements are easy to quantify in your follow-up reporting to stakeholders.
- Documentation — If your audit uncovered ownership gaps and tribal knowledge risks, documentation is the fix. This means creating clear lineage descriptions, component-level documentation, and flow READMEs that make it possible for anyone on the team to understand what a pipeline does, why it exists, and how it connects to the broader system.
Documentation is also the bridge between resolving existing debt and preventing new debt — which is why I recommend tackling it with agents from the start (more on that in Step 4).

Doing all four of these manually? That's months of painstaking work. This is where I get excited — because this is exactly what AI agents are built for.
The agentic approach
Agents are remarkably good at identifying patterns across codebases, which makes work like deduplication, optimization, and documentation almost trivial for them. But an agent needs the right architecture to be effective. Specifically, it needs three things:
- Code access — The ability to read your existing ingest, transform, and orchestration code. This is what tools like Cursor and GitHub Copilot provide. But for data engineering, that's only part of the picture.
- Runtime access — This is the differentiator. An agent that can not only see your code but also run pipelines, monitor performance, identify bottlenecks, and test optimizations autonomously is fundamentally more powerful. It creates a feedback loop: write code → test it → validate the output → iterate. That loop is what makes an agentic data engineering approach so much faster than manual remediation.
- Guardrails — These come in many categories but two critical ones I’ll highlight are 1) a clear separation between development and production, and (2) the ability to monitor and customize agentic behavior. You want agents experimenting freely in a contained development enviornment but requiring human approval before anything touches production code. And you want the ability to assert your standards and practices.
At Ascend, this is the architectural approach behind Otto — our AI agent operates with full context of your code, runtime history, and data lineage, but within clearly defined safety boundaries. When it identifies an optimization or suggests a migration approach, it tests in an isolated workspace and presents validated results for review.
Step 4: Prevent New Debt
Reducing existing tech debt is only half the battle. Without a prevention strategy, you'll end up right back here in a year.
The most powerful prevention approach I've seen is programming your AI agents with explicit rules that enforce quality standards by default.
If you're not familiar with the concept, think of rules as the instructions you give your agent about how to behave — not just for a single task, but persistently across everything it does. They're typically short markdown files (often just 20–30 lines) that define standards, conventions, and expectations. When an agent has rules loaded into its context, it follows them every time it writes code, generates documentation, or suggests optimizations. It's like onboarding a new engineer with your team's best practices, except the agent never forgets them and applies them consistently.
In Ascend, rules live as .md files in your project and are configured to inject additional context dynamically into the agent’s system instructions. But the concept applies regardless of platform — any agentic system worth using should give you a way to define persistent behavioral rules.
There are three rule types I recommend every team start with:
Learning rule
These create a structured improvement loop. Every time the agent works on your pipelines and receives feedback, it captures that knowledge — updating its understanding of your patterns, conventions, and edge cases. This means the agent gets more effective over time, and institutional knowledge that used to live only in one person's head gets preserved in the system.
What this looks like in practice: A learning rule tells the agent when to propose new rules (when a user corrects a mistake, when it discovers a project-specific pattern, when it finds a workflow shortcut), and sets quality standards for those proposals — rules must be clear, concise, non-duplicative, and non-conflicting. It also defines a process: identify the learning, check for overlap with existing rules, propose with clear reasoning, and wait for confirmation before making changes.
The result is that your agent builds a growing knowledge base of how your specific team works — not generic best practices, but the actual patterns and preferences that make your pipelines yours.
Business logic rules
These document your standards, implementation patterns, and quality requirements. Here's what I love about this: you don't have to write these from scratch. An agent with code access can analyze your existing codebase and infer your business logic, then present it for your review. You might even be surprised — there may be patterns embedded in your code that you didn't realize existed. Once codified, these rules ensure every new pipeline adheres to your standards automatically.
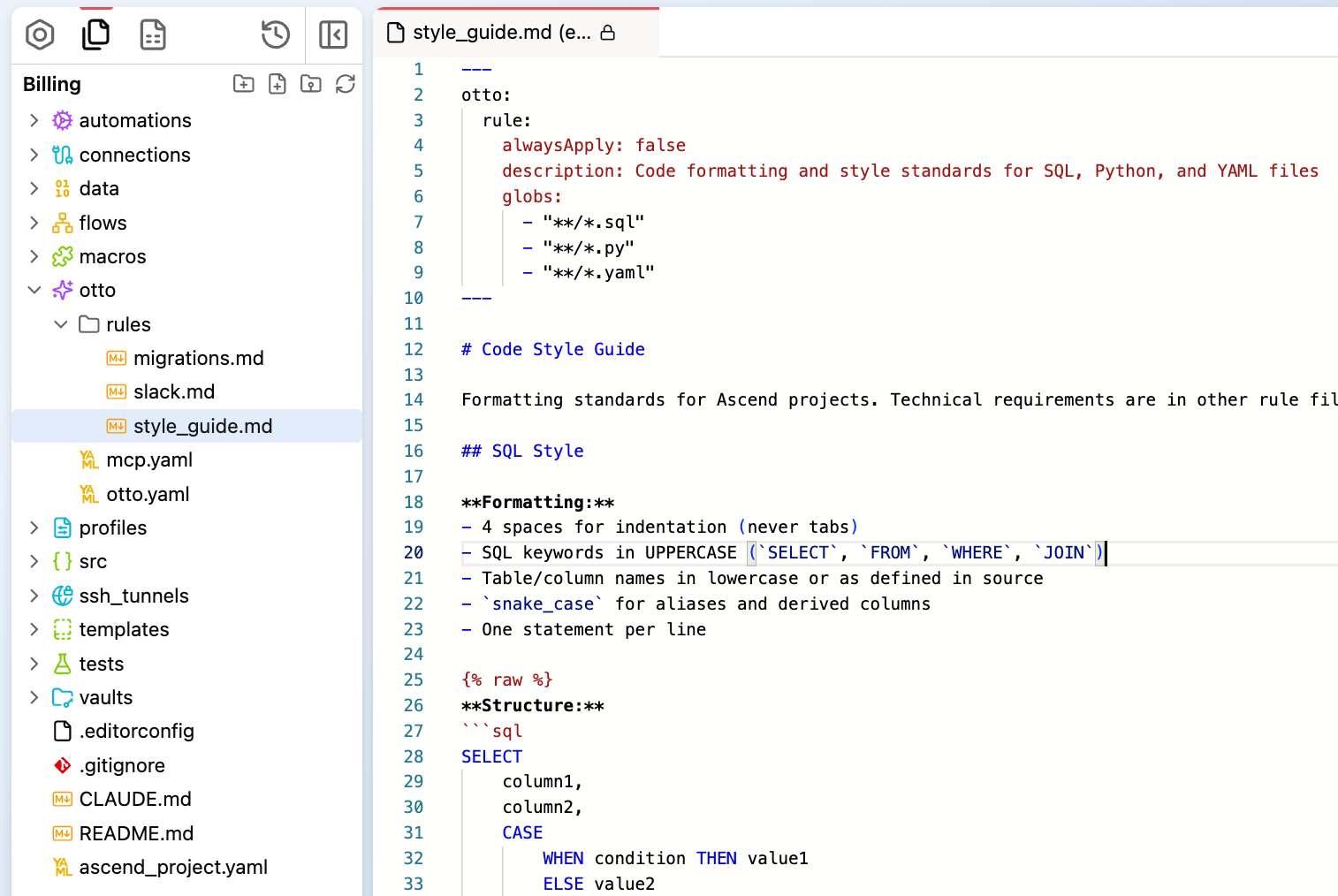
What this looks like in practice: A business logic rule might specify that every SQL or Python transform needs a comment block at the top explaining the component name, its purpose, the business rules it implements, its dependencies, and when it was last updated. It might define that cancelled orders should always be excluded with status != 'cancelled', that regional discount rates should always come from the lookup table, and that currency amounts should always be converted to USD using daily exchange rates. It can also define how flow-level READMEs should be structured — documenting data lineage step by step, key business rules, and known edge cases.
The power here is that once these rules exist, every piece of code the agent helps build or review automatically conforms to them. No more hoping individual developers remember to follow the conventions your team agreed on six months ago.
Documentation maintenance rules
Instead of relying on engineers to remember to update docs after every change (let's be honest — that never happens consistently), a documentation rule tells the agent to automatically update READMEs, lineage descriptions, and component documentation whenever code changes. In Ascend, this is about 31 lines of configuration that eliminates an entire category of manual work and a major source of future tech debt.
The shift here is fundamental: tech debt prevention goes from a discipline problem (hoping every engineer follows best practices every time) to a systems problem (programming the agent to enforce those practices by default). When your team is co-building with agents that have these rules embedded, quality standards are maintained without anyone having to think about it.
Get Started
If you're staring at a mountain of tech debt, the most important takeaway is this: start now, start imperfectly. Talk to your engineers, identify your top pain points, quantify the business impact, and begin tackling the highest-priority items.
And as you work through resolution, invest early in prevention. The rules you set up for your agents today will pay dividends for years — not just in avoided tech debt, but in accelerated delivery of the new data products your business is waiting for.
Want to go deeper? If you want hands-on help building a practical implementation plan for your environment, Book some time to talk with our team →



.avif)
