Every year, our team surveys data teams across industries to understand how they spend their time. One number stood out this year: data engineers spend 50% of their time on maintenance. Not building new features, not solving interesting problems—just responding to broken pipelines.
That stat matches what I hear from data engineers every week. Someone's always getting paged at 2 AM for a pipeline failure, spending an hour digging through logs and recent commits, then writing up the same type of incident report they've written dozens of times before. Code reviews pile up waiting for a senior engineer to have time to get to them. Performance issues get addressed reactively when the cloud bill spikes.
These are smart people doing repetitive work that frankly, AI should be handling. So we built DataOps Agents to do exactly that.
In this post, I'll walk you through how teams use AI to automate the manual work of DataOps. I’ll also cover how we built this safely (because nobody wants AI touching production data without guardrails) and how teams can customize agents to fit their specific workflows.
I. Defining DataOps in the Modern Data Stack
DataOps as a term gets used pretty loosely across the industry, so let me be clear about what we mean when we talk about it in the context of agentic operations.
As we've outlined in our DataOps implementation guide, DataOps is the set of practices that keep your data pipelines running smoothly at scale. The primary objective is improving the speed, quality, and reliability of data through automation and orchestration.
DataOps isn't simply DevOps applied to data—data workflows have unique operational challenges. Schemas evolve continuously, pipelines must handle variable scale and complexity, and unlike application deployments, you can't easily roll back data that's already been consumed by downstream systems.
The foundational components include:
- Automation: Eliminating manual intervention in repetitive data pipeline tasks
- Orchestration: Coordinating data processes across systems to ensure seamless data flow
- CI/CD for data: Applying continuous integration and delivery practices to data pipeline deployments
- Continuous monitoring: Real-time visibility into pipeline performance and data quality
- Cross-team collaboration: Aligning data engineers, analysts, and business stakeholders around shared data objectives
Most organizations start with basic practices—version control for pipeline code and some level of monitoring. As DataOps maturity increases, teams implement sophisticated deployment workflows, automated data quality validation, resource optimization, and structured incident response processes.
The critical distinction is that DataOps focuses on operational excellence, not just during development. Data engineers build and optimize pipelines; DataOps ensures those pipelines run reliably in production, handle edge cases appropriately, and maintain consistent performance at scale.
The challenge with traditional DataOps implementations is the heavy reliance on manual processes. Teams repeatedly perform the same investigative tasks, follow identical troubleshooting procedures, and manually correlate context when issues arise. This operational overhead represents exactly the type of pattern-based, context-driven work that agents can take on easily.
II. The Three Ingredients for Effective DataOps Agents
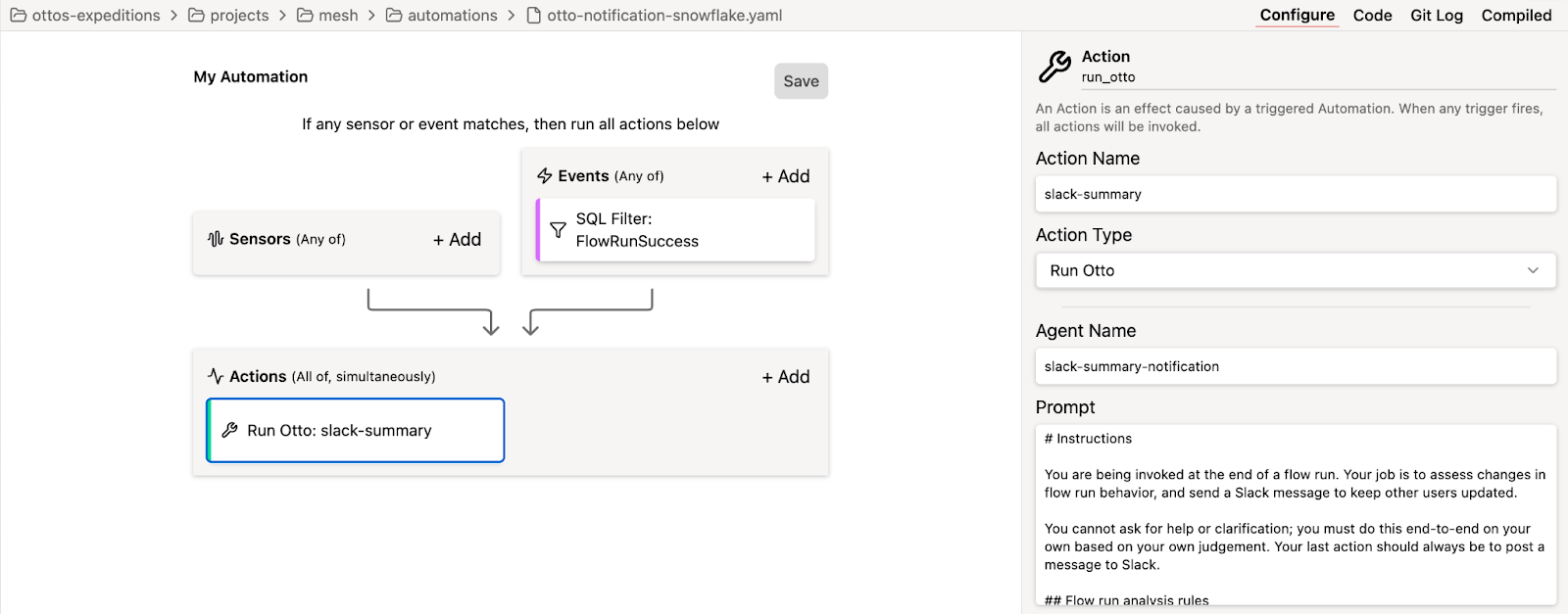
For DataOps agents to move beyond simple notification bots and actually handle complex operational work, you need three key ingredients working together: 1) reliable triggers, 2) comprehensive context, and 3) meaningful actions. Get any of these wrong, and your agents become expensive notification systems instead of operational force multipliers.
Triggers: How Agents Know When to Act
Agents are only as good as their ability to respond to the right events at the right time. Ascend supports two primary trigger mechanisms that cover the full spectrum of operational scenarios.
System events represent the reactive triggers that respond to things happening in your data platform. For example, pipeline runs, successes, failures, and data quality test violations all generate system events that can initiate agent workflows. These triggers ensure agents respond immediately to operational conditions as they occur rather than discovering issues hours later through manual monitoring.
Sensors provide proactive triggers through scheduled execution or custom Python functions. Some operational tasks need to happen on a regular cadence—cost optimization analysis, performance trend monitoring, or compliance reporting. Sensors let you define these scheduled workflows or create custom logic that evaluates specific conditions and triggers agent actions when thresholds are crossed.
The combination means agents can handle both reactive incident response and proactive operational maintenance within a single framework.
Context: The Information Agents Need to Act Intelligently
Context is what transforms simple automation into intelligent operational assistance. When a pipeline fails, an agent needs access to the same information a senior data engineer would gather during investigation—but instantly and comprehensively.
Within Ascend, agents access:
- Code: Including SQL transformations, Python scripts, and configuration files that define your pipelines. Agents can analyze recent changes, understand dependencies between components, and identify patterns in code modifications that might explain operational issues.
- Metadata: Schemas, volumes, and quality metrics. When investigating a pipeline failure, agents can determine whether the issue stems from upstream data changes, volume spikes, or quality problems that weren't caught by existing validation.
- User actions: Git history shows who made what changes when, while run patterns reveal how teams typically interact with specific pipelines. This context helps agents understand whether issues might be related to recent human modifications.
- Infrastructure: job status, compute usage, resource allocation, and performance metrics. Agents can correlate operational issues with infrastructure constraints or identify optimization opportunities based on actual resource utilization patterns.
- Lineage and dependencies: the relationships between data assets, showing how changes in one pipeline might impact downstream consumers. This context is crucial for understanding the blast radius of potential issues and prioritizing remediation efforts.
- Errors and incidents: logs, anomalies, and historical incident patterns. Agents can search past incidents for similar error signatures and reference successful resolution strategies from previous operational issues.
This context means agents have a rich understanding of your data and can operate with much of the same context as a member of your team.
Actions: How Agents Interact with Your Operations
Context without action is just expensive monitoring. The real value emerges when agents can take meaningful steps to resolve issues, improve systems, and reduce operational overhead. Within Ascend, agents have the power to:
Research: Agents analyze code quality, investigate performance history, correlate incidents with recent changes, and identify optimization opportunities. These actions handle the investigative work that typically consumes significant engineering time during incident response.
Alert: Agents can open GitHub issues with detailed context, create incident records in monitoring systems, and escalate critical problems through appropriate channels. Rather than generic notifications, these actions provide structured, actionable information that accelerates resolution.
Notify: Agents can send targeted emails and messages to the right people with relevant context. Instead of waking up the entire on-call rotation, agents can route specific issues to the engineers most likely to resolve them quickly based on code ownership and expertise patterns.
Draft: The most advanced of agent capabilities— with the proper context and tools, agents can prototype initial fixes, generate code changes, and prepare pull requests for human review. These actions handle the mechanical work of implementing solutions while maintaining human oversight for critical decisions.

The power emerges when these three ingredients work together. A pipeline failure triggers the agent, which gathers comprehensive context about recent changes and historical patterns, then takes appropriate research and notification actions to accelerate resolution. It's the same workflow an experienced engineer would follow, but executed consistently and immediately every time.
WATCH NOW: From Old School to Agentic: AI for Data Ops
III. DataOps Agents: Architecture and Capabilities
Once you have these core ingredients in place, the question becomes: what can these agents actually accomplish? The real value emerges when agents start handling the complex, context-heavy operational work that typically requires human intelligence.
Here are some real-world scenarios that show how agents transform day-to-day DataOps work:
The 3 AM Pipeline Failure
The old pattern: Your critical customer analytics pipeline fails at 3 AM. You get paged, roll out of bed, and start the investigation. First, you check the error logs—some vague schema error. Then you dig through Git to see who committed what in the last 24 hours. Sarah updated the user table transform yesterday, but that seems unrelated. You check the upstream data source and discover the marketing team added a new field without telling anyone. Forty-five minutes later, you've got a temporary fix and a tension headache.
The agentic workflow: The pipeline fails, and within 60 seconds you get a Slack message: "Customer analytics pipeline failed due to unexpected column 'utm_campaign' in users table. Marketing team's ETL job added this field 6 hours ago. I found a similar issue from last month where we handled new marketing columns by updating the schema mapping in user_transforms.sql. I've created a draft PR with the fix based on that previous resolution."
The "What Changed?" Investigation
The old pattern: Your weekly sales report is showing weird numbers. You spend two hours tracing through the pipeline, checking each transformation step, reviewing recent commits across four different repositories, and finally discover that someone updated a join condition three days ago that's causing duplicate records.
The agentic workflow: The data quality check fails and the agent immediately correlates the anomaly with recent changes. It messages your team: "Sales report showing 23% increase in row count. Root cause: join condition modified in sales_aggregation.sql by Jake on Tuesday. Change introduced duplicate customer records. Previous version of this logic is in git hash abc123. "
Code Review Backlog
The old pattern: Your team has six open PRs waiting for review. Each reviewer needs to check if the code follows your partitioning standards, includes proper error handling, has appropriate data quality tests, and follows naming conventions. Reviews take 2-3 days because everyone's busy with their own work.
The agentic workflow: Every PR gets a reviewed within minutes. The agent checks your team's coding standards, validates that new tables include proper partitioning, ensures data quality tests are present, and flags any deviations from established patterns. Human reviewers only need to focus on business logic and architecture decisions rather than style and compliance issues.
Pipeline Performance Degradation
The old pattern: Your monthly data processing costs jumped 40% but you have no idea why. You spend a day analyzing query performance across dozens of pipelines, trying to correlate cost spikes with recent changes or data volume increases.
The agentic workflow: The monitoring agent notices the increase and automatically investigates. It identifies that three pipelines are now processing full table scans instead of using incremental updates due to a configuration change last week. The agent provides specific recommendations: "Switch back to incremental processing for these three flows, estimated monthly savings: $2,400."
These examples represent just a fraction of what's possible with DataOps agents. With custom built agents and MCP (Model Context Protocol) servers, teams can automate virtually any operational workflow they can imagine. Whether it's integrating with your specific monitoring tools, implementing custom data quality checks, or automating compliance reporting for your industry, the only real limit is creativity in defining what you want automated.
IV. Safety and Governance in Agent Operations
The prospect of autonomous agents making changes to production data systems understandably makes data engineers nervous. The key to successful agent deployment is implementing the right guardrails and governance frameworks to manage risk effectively.
Environment-Specific Permissions
Agent permissions should follow the principle of graduated trust. In development environments, agents can have broad permissions to experiment, test fixes, and iterate on solutions. They can modify code, update configurations, and even deploy changes within the isolated development context.
Production environments demand the most conservative approach. Agents within Ascend are limited to read-only operations and notification capabilities within production environments. They can investigate issues, gather context, and propose solutions, but implementation requires explicit human authorization.
Version Control as a Safety Net
The version-controlled foundation we discussed earlier becomes critical for agent safety. Every action an agent takes—code modifications, configuration changes, pipeline updates—gets tracked through standard Git workflows. This creates an automatic audit trail and recovery mechanism.
If an agent makes a problematic change, reverting is as simple as a standard Git rollback. The version control history shows exactly what the agent modified, when it made the change, and what triggered the action. This transparency is essential for debugging agent behavior and building team confidence in automated operations.
Human-in-the-Loop Workflows
Not every operational task should be fully automated. Critical decisions—like schema changes that affect downstream consumers or modifications to production data pipelines—benefit from human oversight even when agents can handle the technical implementation.
Effective human-in-the-loop workflows present agents' analysis and proposed solutions to human reviewers for approval. The agent does the investigative work, gathers context, and suggests specific actions, but humans make the final decision about implementation. This approach captures most of the efficiency benefits while maintaining human control over high-stakes decisions.
Audit Trails and Observability
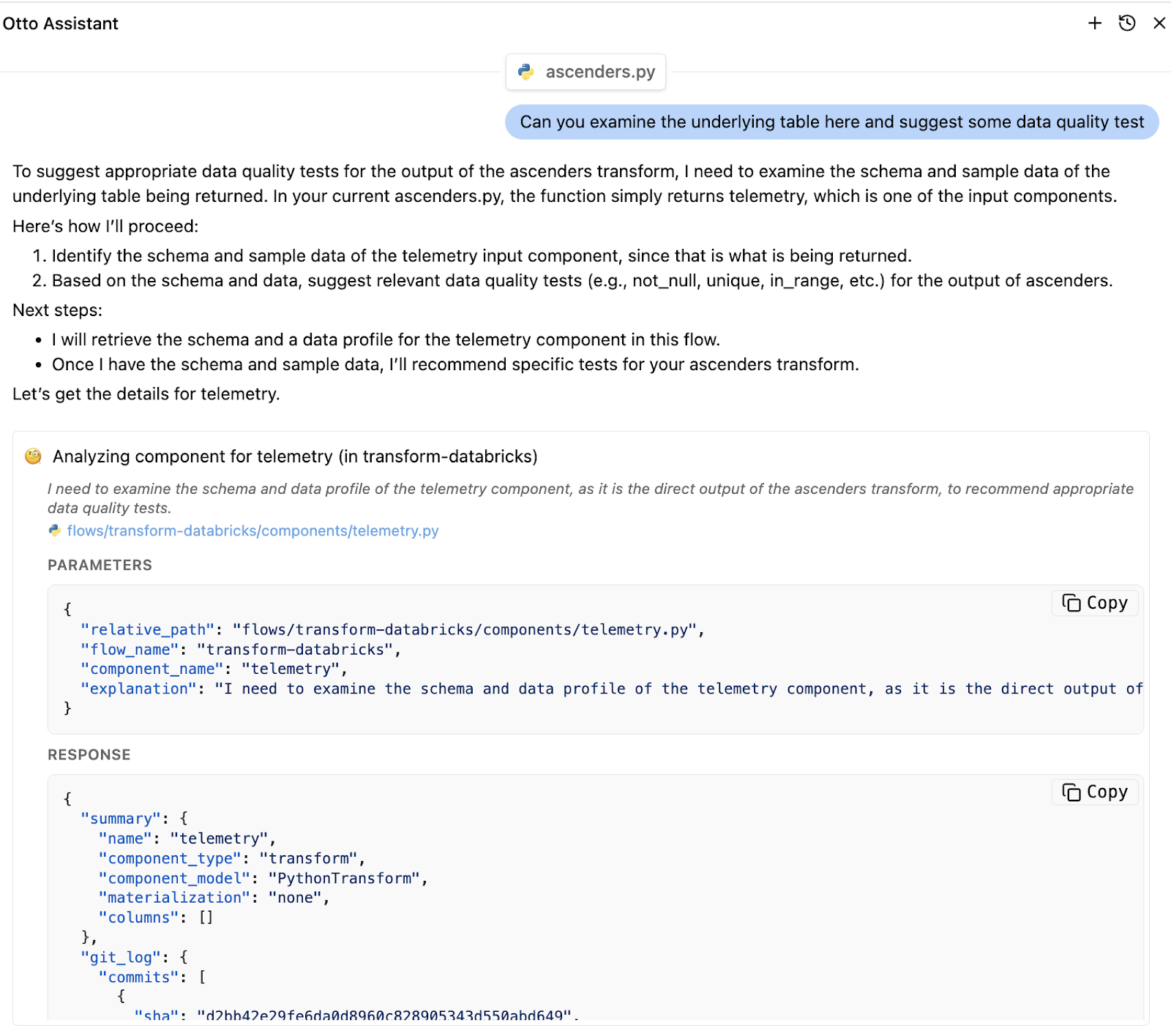
Comprehensive logging becomes essential when agents are making autonomous decisions. Every agent action should be logged with sufficient detail to understand the agent's reasoning, the context it considered, and the specific changes it implemented.
Effective audit trails capture not just what agents did, but why they did it. This includes the events that triggered agent actions, the data sources the agent consulted, the historical patterns it referenced, and the decision logic it applied. This level of detail enables teams to validate agent behavior and identify potential improvements to agent logic.
The goal isn't perfect automation—it's reliable automation with appropriate oversight. When designed thoughtfully, agentic frameworks enable teams to capture significant operational efficiency while maintaining the safety and control necessary for production data systems.
Conclusion: From Reactive to Proactive Data Operations
The shift from manual DataOps to agentic DataOps represents more than just automation—it's a fundamental change in how data engineering teams operate. Instead of constantly reacting to pipeline failures, data quality issues, and operational overhead, teams can focus on building better data systems while agents handle the routine operational work.
The paradigm shift is about leverage. A single data engineer working with intelligent agents can handle the operational workload that previously required multiple people. The agents don't replace engineering judgment—they amplify it by handling the investigative work, context gathering, and routine maintenance that currently consumes so much engineering time.
We're seeing teams realize ROI within weeks of deploying their first agents. The time savings from automated incident response alone often justifies the investment, but the real value compounds as teams deploy agents for code review, pipeline optimization, and proactive monitoring. Engineers report feeling less like they're constantly fighting fires and more like they're building strategic data capabilities.
The key insight is that agents need the right foundation to be effective. You can't drop AI into a chaotic data environment and expect magic. But when you have proper DataOps practices—version control, structured projects, safe deployment workflows—agents become incredibly powerful operational multipliers.
