The $12 That Powers 80 Billion Records
Your daily lunch costs more than our data pipelines.
Two months ago, that statement would have been absurd. Today, it's our reality: we maintain an 80-billion-record dataset with continuous updates and multiple downstream workflows for under $12 daily on Snowflake. That's less than a sandwich and coke in most cities, yet it powers the data operations for our entire organization.
This isn't a clever accounting trick or a limited proof-of-concept. This is our actual daily operating cost for a production system that processes billions of records, handles late-arriving data, supports dozens of downstream applications, and maintains sub-hour freshness across the entire pipeline.
The transformation happened because we built something profound: our Smart Table capabilities that function like enhanced incremental transformations, ensuring we only process what has actually changed rather than reprocessing the entire dataset. What truly enabled this transformation was the integration of AI agents serving as collaborative partners throughout the migration journey—translating code, resolving errors, and providing continuous pipeline monitoring.
What you're about to read isn't just a migration story. It's a blueprint for transforming your data infrastructure from an expensive burden into a strategic asset that costs less than lunch.
The Starting Line: Why We Had to Move
Six months ago, our Apache Spark infrastructure was limiting our innovation.
Spark had served us exceptionally well for years, providing reliable service as our data volumes grew. But like any mature technology stack, it eventually revealed limitations as our requirements evolved. We encountered familiar scaling challenges that many organizations face: escalating operational overhead, increasing infrastructure costs, and our engineering team spending disproportionate time on system maintenance rather than innovation. The breaking point came when these pain points signaled it was time for strategic change.
After comprehensive evaluation, Snowflake emerged as the clear choice. Its architecture—featuring instant elasticity, zero-copy cloning capabilities, and true compute-storage separation—offered the foundation we required. The transformative element came from integrating our Gen 3 architecture with Snowflake's capabilities.
This represented more than a technology migration—it was a strategic platform decision. Our deep Snowflake integration enabled us to leverage native features like Snowpark for Python while adding intelligent automation through DataAware™ technology. This combination delivered what neither platform could provide independently: a unified data automation approach with embedded AI agents, comprehensive pipeline visibility, and real-time optimization capabilities.
The Anatomy of Impossible Economics
When we tell people we run 80 billion records for $12 a day, the first reaction is always skepticism. The second is "show me the math."
The secret isn't in buying cheaper compute—it's in processing smarter. Our transformation centers on intelligent processing rather than brute-force computation, with every dollar spent deliberately rather than defensively. Here are the 3 primary ways we optimized costs in our migration:
1. Strategic Warehouse Configuration
Rather than defaulting to oversized compute resources, we implemented precise workload routing strategies:
- Ingestion Workloads: We deploy Gen 1 X-Small warehouses with horizontal scaling through multi-cluster capabilities (requiring Enterprise edition, but delivering exceptional ROI). During backfill operations, we can orchestrate over 80 parallel workers, achieving optimal price-performance ratios.
- Transformation Workloads: We deploy Gen 2 Large warehouses, also configured with multi-cluster scaling capabilities, though standard operations rarely require full scaling. The enhanced caching and query optimization in Gen 2 significantly improves complex transformation performance.
This approach means we're never paying for idle capacity we don't need, but we can instantly scale to massive parallelism when we do.
2. Intelligent Data Processing with Smart Components
Our Smart Components revolutionized our approach to the 80-billion-record dataset, intelligently partitioning data into time-series sub-queries:
- Daily updates typically affect only 0.1% of total data (approximately 80 million records)
- Late-arriving data is handled gracefully without triggering full reprocessing
- Pipeline logic updates only recompute affected partitions
- Backfills execute with surgical precision
The beauty? If we need to update our pipelines hourly instead of daily, the cost barely changes—we're still only processing the deltas. This is the difference between traditional batch processing (reprocess everything) and intelligent incremental processing (process only what changed).
3. Optimized Materialization Strategy
Our approach to materialization is strategic and cost-conscious:
- Materialize tables when significant record transformations or heavy computations justify the investment
- Utilize views elsewhere to maintain clean, refactored flows without unnecessary storage and compute expenses
- Leverage AI agents to analyze query patterns and recommend optimal materialization strategies
This approach reduced storage costs by 60% while enhancing query performance.
4. Streamlined Data Ingestion
Consolidating our diverse ingestion landscape delivered significant operational improvements:
- S3 and GCS: Ascend's framework seamlessly manages cloud storage ingestion, automatically detecting new files and schema evolution
- PostgreSQL and MySQL: Our optimized incremental ingestion captures only changes without impacting source system performance
- Kafka: Real-time streams process with exactly-once semantics
- Complex CSV Files: Robust parsing handles varying delimiters, inconsistent formatting, and character encoding challenges
And, our observability data provides real-time insights into ingestion performance. When patterns shift—such as daily files becoming hourly or source volumes growing exponentially—we adjust strategies based on concrete metrics.
5. Multi-Language Optimization
One of the most liberating aspects of our new architecture was escaping one-size-fits-all solutions. We now optimize by selecting the right tool for each task:
- SQL for what it's best at: set-based operations and aggregations
- Python for complex business logic and ML preprocessing
- The Right Tool for the Right Job: Our AI agents even help decide which language to use based on the transformation pattern
This flexibility through Snowflake's Snowpark eliminated forced architectural compromises that had accumulated over years. Instead of writing convoluted distributed code to handle simple aggregations, we could write clean SQL. Instead of expressing complex business rules awkwardly, we could use Python's expressive power.
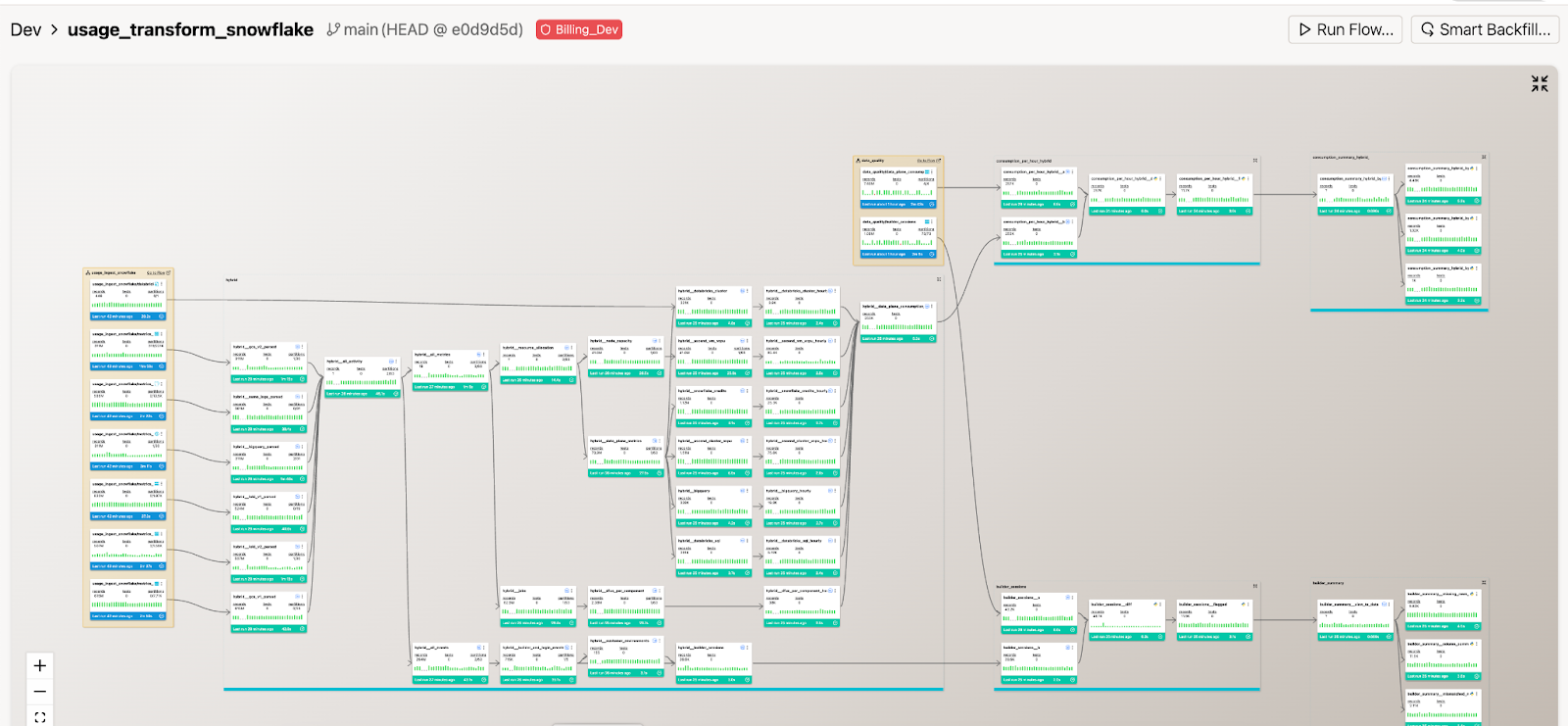
Building on a Modern Data Platform
A successful migration isn't just about moving code from one platform to another—it's about building the foundation that makes future innovation possible. The difference between a migration that succeeds and one that creates new challenges lies in the architecture decisions you make along the way.
The Ascend platform was built with these best practices at the core, which enabled us to migrate faster, safely.
1. Comprehensive Git Integration
Every pipeline, transformation, and configuration now lives in Git. Ascend’s deep integration with Git means that all changes are tracked and code is managed safely. This isn't just about version control—it's about:
- creating complete audit trails for every change
- enabling instant rollbacks when issues arise
- implementing true branching strategies for data pipelines
This means we can build and test changes (like schema migration, for example) in isolation.
2. CI/CD That Protects Production
We've built robust CI/CD that extends beyond basic testing.
- Automated testing triggers on every commit against production-representative data samples.
- Schema changes automatically propagate across environments with full validation at each stage.
- AI agents review pull requests for performance implications before they reach production.
Engineers can ship with confidence because the safety net is comprehensive and automated.
3. Unified Observability: Data About Data
Instead of managing fragmented logs across multiple systems, we centralize observability data in Snowflake itself. This lets allows us to
- query pipeline metrics using familiar SQL
- join operational and business data for comprehensive insights
- eliminate the context switching between disparate monitoring tools that slows down debugging sessions.
When performance degrades, we can immediately correlate it to code deployments. When pipeline costs shift, we can trace the changes back to specific transformations. When data quality issues emerge, we can see the full context of what changed and why.
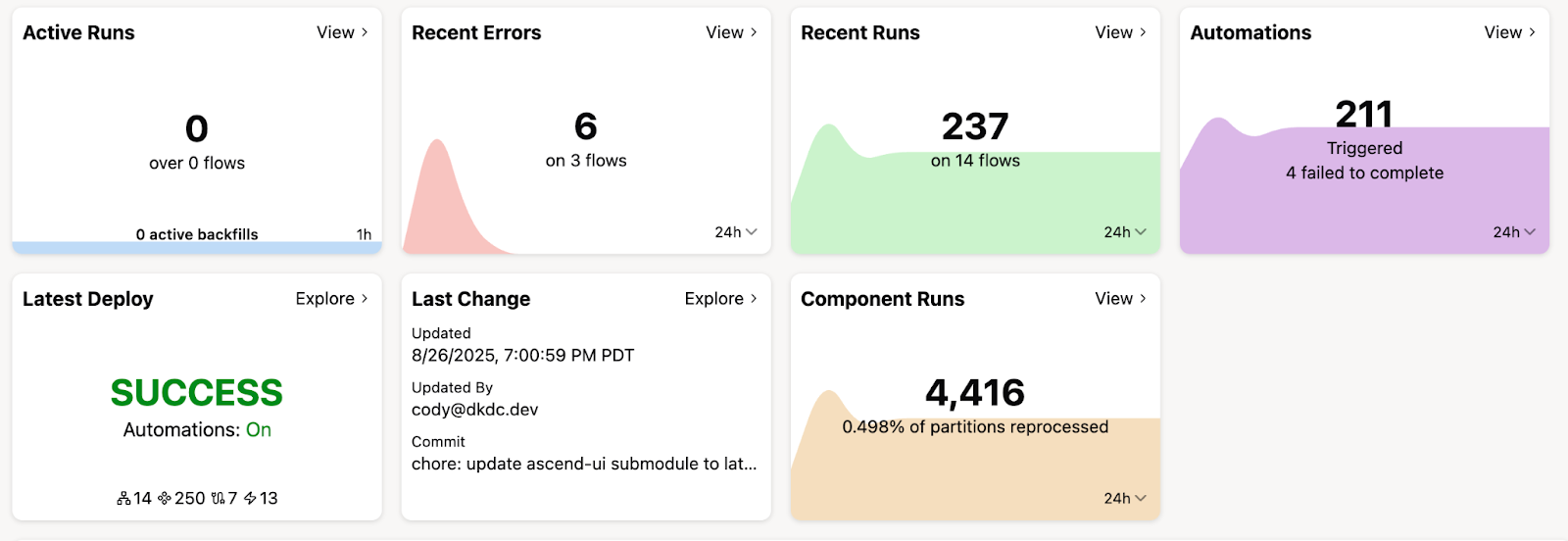
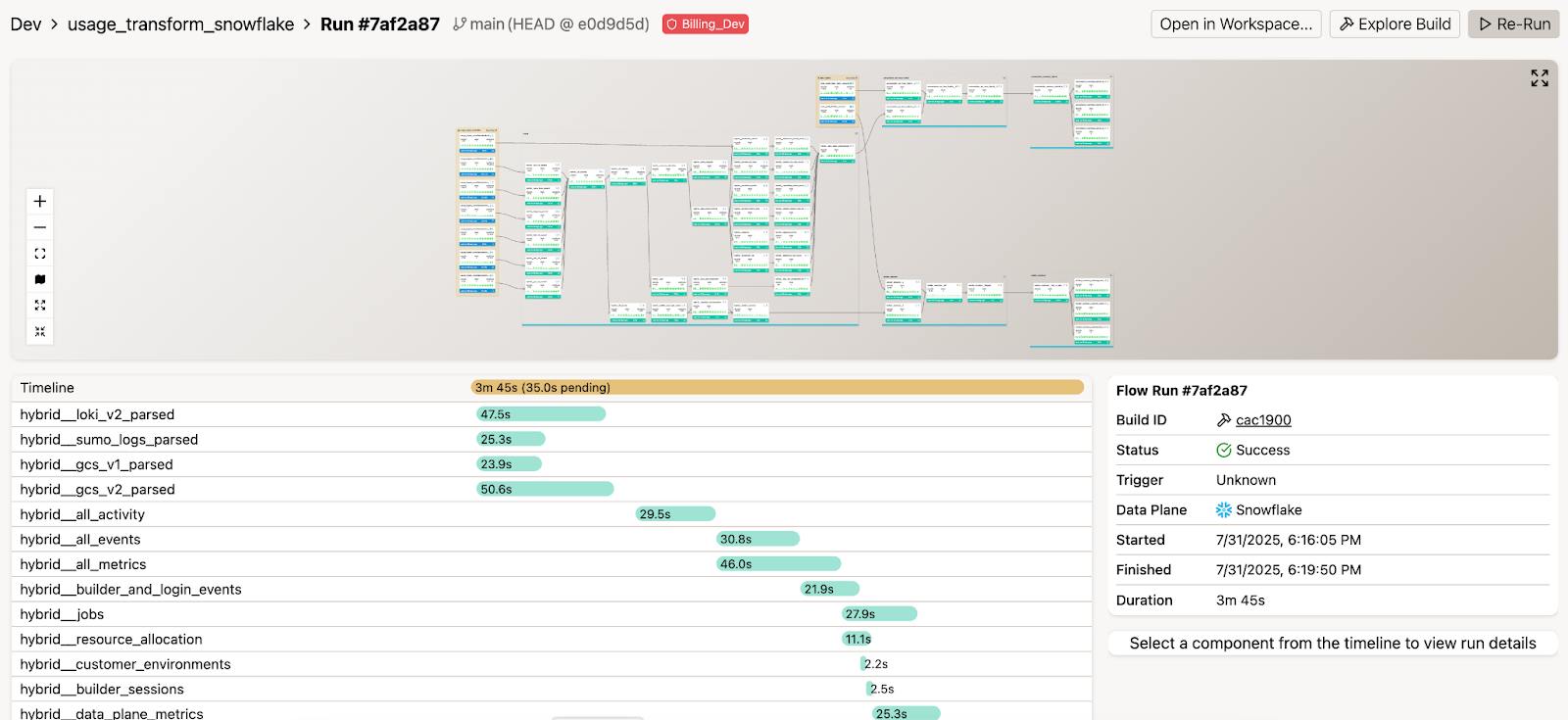
4. Effective Development Environments
We achieved truly isolated development, staging, and production environments without excessive costs. Developers can access production-like data instantly, changes undergo thorough testing against realistic data volumes, and production remains protected until validation completes.
This eliminated the classic data engineering paradox where development environments are too small to catch real problems, but production environments are too risky for experimentation. Engineers could iterate quickly on real-scale data while maintaining the safety and isolation they needed to work confidently.
5. Data Applications: The Unsung Heroes
Ascend Applications provided reusable solutions for common data engineering challenges, allowing us to leverage pre-built functionality rather than developing everything from scratch.
Two applications proved invaluable during our migration:
Data Comparison Application: This systematically validated that our Snowflake pipelines produced identical results to our Spark pipelines, catching edge cases that manual validation would miss. Instead of spot-checking samples or writing custom validation scripts, we could compare massive datasets comprehensively and automatically.
Template Management System: We created reusable sub-flow templates deployed across pipelines, eliminating code duplication and preventing inconsistencies. Instead of copy-pasting code and hoping we updated all instances correctly, we could change templates once and deploy everywhere. This alone saved weeks of development time and prevented dozens of potential bugs.
AI Agents: The Migration Multiplier
The difference between a successful migration and a disaster isn't the technology you choose—it's whether you have the right partner helping you make thousands of critical decisions along the way.
AI agents proved essential to our migration success, but not in the way we initially expected. We thought they'd be helpful assistants. Instead, they became collaborative partners that fundamentally transformed every phase from a manual engineering challenge into an intelligent, guided process.
During the Migration: AI Does The Heavy Lifting
Automated Code Translation became our first breakthrough. Agents converted thousands of Spark code lines into optimized SQL and Python, but this wasn't literal translation—it was intelligent refactoring that leveraged Snowflake's strengths. Where our Spark code used complex distributed processing patterns, agents recognized opportunities to use Snowflake's native capabilities.
Advanced Error Resolution compressed weeks of debugging into hours. When we encountered issues, agents analyzed logs, proposed solutions, and implemented corrections. Complex debugging sessions that historically consumed weeks of engineering time resolved in a fraction of the time.
Pattern Recognition accelerated everything. Agents identified common Spark patterns and automatically applied Snowflake best practices. Instead of our engineers having to research and implement best practices for every transformation, agents handled the bulk of optimization while flagging edge cases that required human attention.
Post-Migration: Ongoing Operational Excellence
The real value became apparent once our migration completed and we entered normal operations. AI agents didn't disappear—they became integral to our ongoing operational excellence.
Autonomous Issue Resolution means pipeline failures trigger immediate agent analysis of errors, recent changes, and proposed fixes before escalation. Instead of engineers receiving cryptic error alerts at 3 AM, they can get notifications that include root cause analysis, proposed fixes, and often automated resolution.
Performance Optimization happens continuously. Agents analyze query patterns, identifying inefficiencies and recommending improvements.
Data Quality Management shifted into development. During development, agents profile data and implement appropriate quality tests, ensuring issues are caught before production.
Context is Key
These agents operate with full context—understanding code, data, errors, and history—providing intelligent reasoning specific to your infrastructure. This means that they understand the relationships between your pipelines, the impact of your changes, and the patterns in your data.
What We Learned (So You Don't Have To)
Every migration teaches you things no documentation could have prepared you for. After two months of running our new infrastructure, here are the insights that matter most.
1. Establish DataOps Foundation First
Before migrating pipelines, build your DataOps infrastructure. Create development environments enabling rapid, safe iteration. Implement CI/CD, promoting changes through proper environments.
We almost made the mistake of starting with pipeline migration instead of proper infrastructure. Teams that skip this step find themselves debugging production issues that proper development environments would have caught.
2. Maximize AI Agent Utilization
AI agents accelerated every aspect of our transformation. They helped
- Translate Spark code to SQL and Python more efficiently
- Debug complex errors by analyzing logs and suggesting solutions
- Profile data to understand quality issues and suggest appropriate tests
- Identify optimization opportunities based on query patterns
We initially thought they'd be helpful assistants. They became essential partners. Teams attempting similar migrations without AI assistance are losing out on valuable resources that could help them move faster.
3. Validate at Production Scale
Small datasets mask performance issues. We learned it’s important to always:
- Use parameters to define the amount of data you are testing in development
- Validate with production-scale data before deploying
- Set up automated performance regression tests
Data quality issues, edge cases in business logic, and resource contention problems all hide in small datasets and reveal themselves at scale. The teams that succeed are the ones that test at production scale early and often.
4. Master Warehouse Optimization
Profile actual workloads to determine optimal configurations:
- We found 2 X-Small warehouses often outperformed 1 Small warehouse for our ingestion patterns
- Multi-cluster scaling isn't always faster—sometimes it's better to queue
- Gen 1 vs Gen 2 performance varies wildly by query pattern
The key insight: optimize based on your actual patterns, not theoretical best practices. Spend time measuring before optimizing, and measure continuously as your patterns evolve.
5. Document Patterns Over Pipelines
Focus documentation on reusable patterns rather than individual pipeline specifications:
- Late-arriving data handling strategies
- Slowly changing dimension approaches
- Standardized error handling frameworks
Let AI agents generate specific pipeline documentation from these patterns. This approach creates knowledge that scales across your entire organization rather than tribal knowledge locked in individual implementations.
6. Plan for Hidden Costs
Budget considerations that teams often overlook:
- Out-of-order time series data handling
- Production-mirroring development environments
- Team SQL optimization training
- Enterprise edition features delivering significant value
These aren't surprise costs if you plan for them upfront. Teams that budget only for compute and storage find themselves scrambling when they discover the operational investments required for success.
The Bottom Line: This Changes Everything
Two months in, we've fundamentally transformed our operations:
- Development velocity: 7x improvement from concept to production
- Operational efficiency: 83% reduction in manual interventions
- Processing costs: 91% lower per TB than Spark infrastructure
- Incident reduction: 94% decrease in on-call events
Conclusion
Two months ago, operational overhead consumed our resources, compute costs escalated continuously, and our engineering talent focused on maintenance rather than innovation. Today, we maintain 80 billion records with continuous updates for less than $12 daily, AI agents proactively identify and resolve potential issues, and our engineers focus on capability development rather than firefighting.
Total infrastructure costs decreased by 87%, but the real victory is that we've rekindled our passion for data engineering. We've evolved from maintenance technicians to architects and innovators.
The technology exists. The patterns are proven. AI agents are ready to accelerate your transformation, intelligent processing can redefine your economics, and modern data architecture can free your team to focus on what matters. The question isn't whether this transformation is possible—we've proven it works at scale. The question is: when will you begin your transformation journey?
