
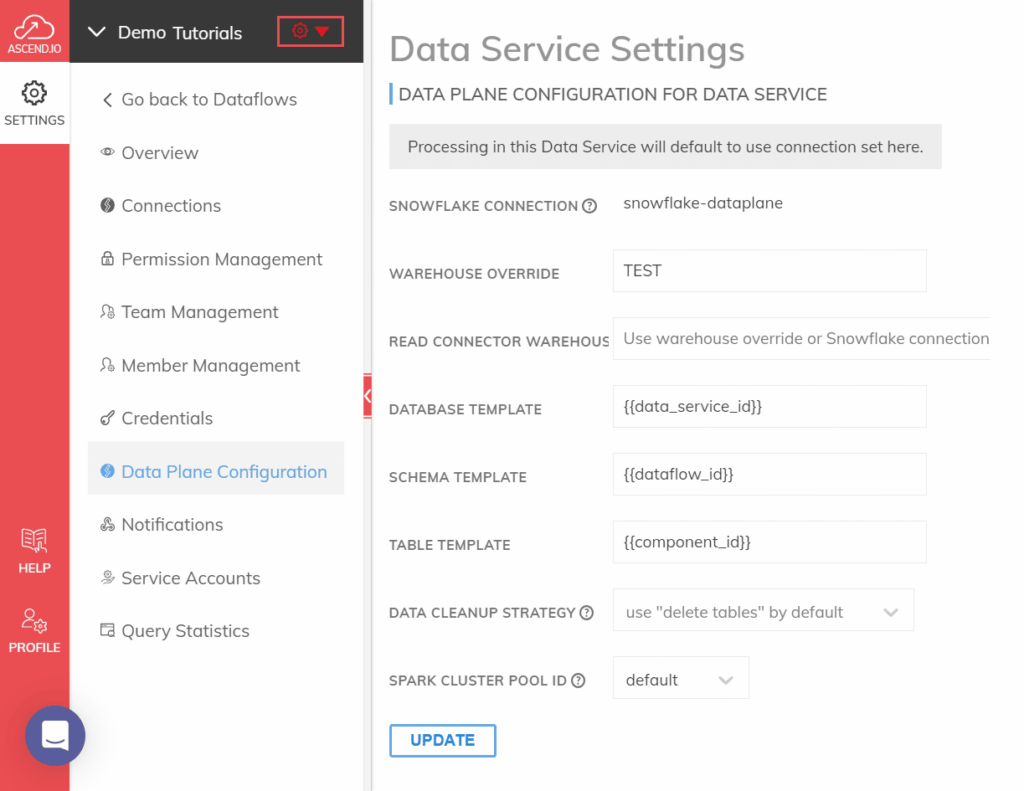
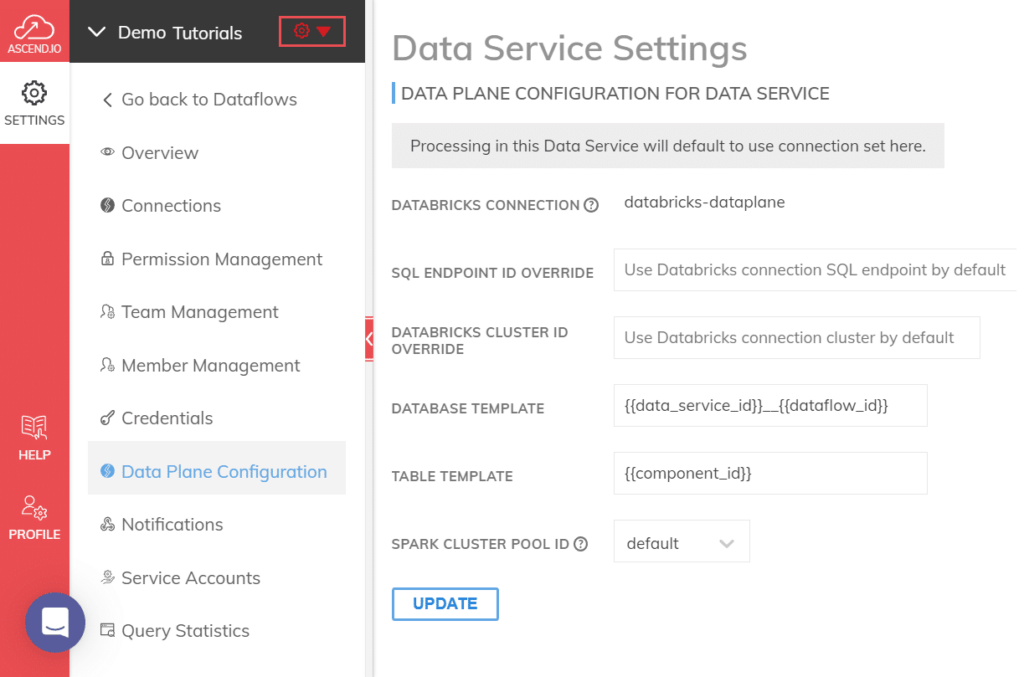
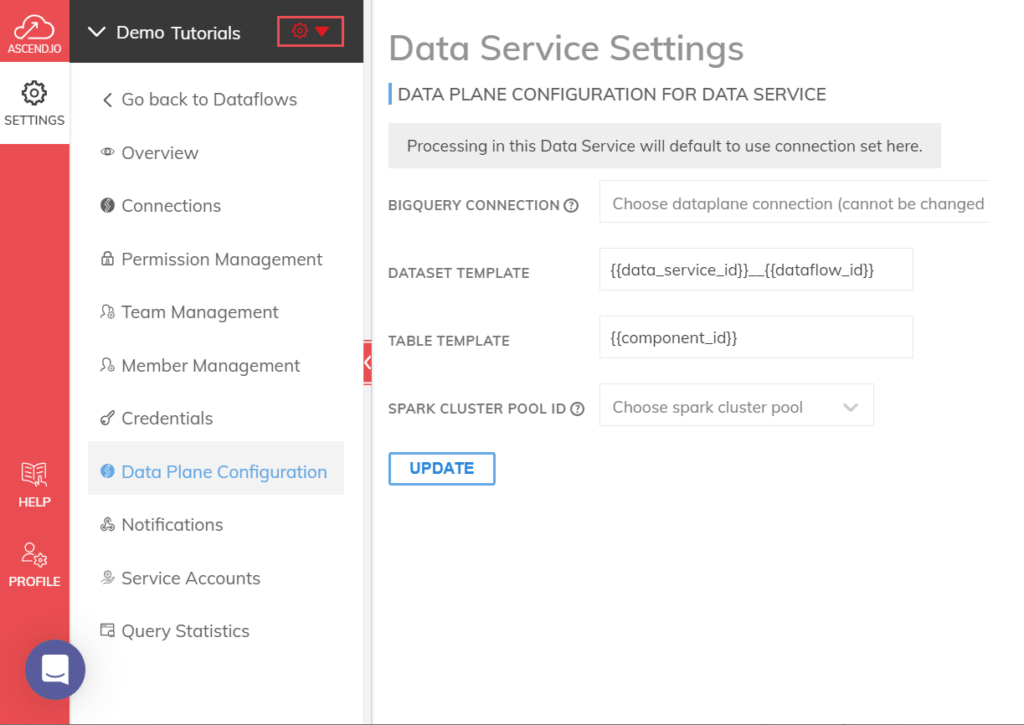




Data engineering is evolving rapidly, driven by advancements in AI and automation. As teams face increasing demands, the need for efficient and effective solutions has never been greater. This article

Learn effective metadata management practices to streamline your data engineering workflows, enhance data quality, & optimize your pipelines.

What is DataOps? Discover benefits, best practices, and implementation strategies to enhance your data workflows and drive business outcomes.