


Beside the usual bug fixes, this week’s release notes touch on upgrades in two essential capabilities:
- Observing costs of running data pipelines in the connected data planes
- Configuring network connections to other systems via the SDK
Let’s take a quick look at these in turn.
Expanded Cost Metrics of Data Planes
This upgrade continues to simplify the observability of Databricks, Snowflake, and BigQuery infrastructure supporting your data pipelines. If you recall, you can configure these data clouds through the Ascend platform, as we outlined in Link Multiple Data Clouds to Ascend on February 6.
Then we discussed the New Data Plane Usage Report on January 26, which pulls together data cloud usage information for costing analysis. Some customers correlate this usage to the timing of data pipeline operations to pinpoint which are more resource intensive. Others direct it into their IT logging systems like Splunk, Datadog, or Sumo for analysis. A few are even using Ascend itself to analyze this usage data.
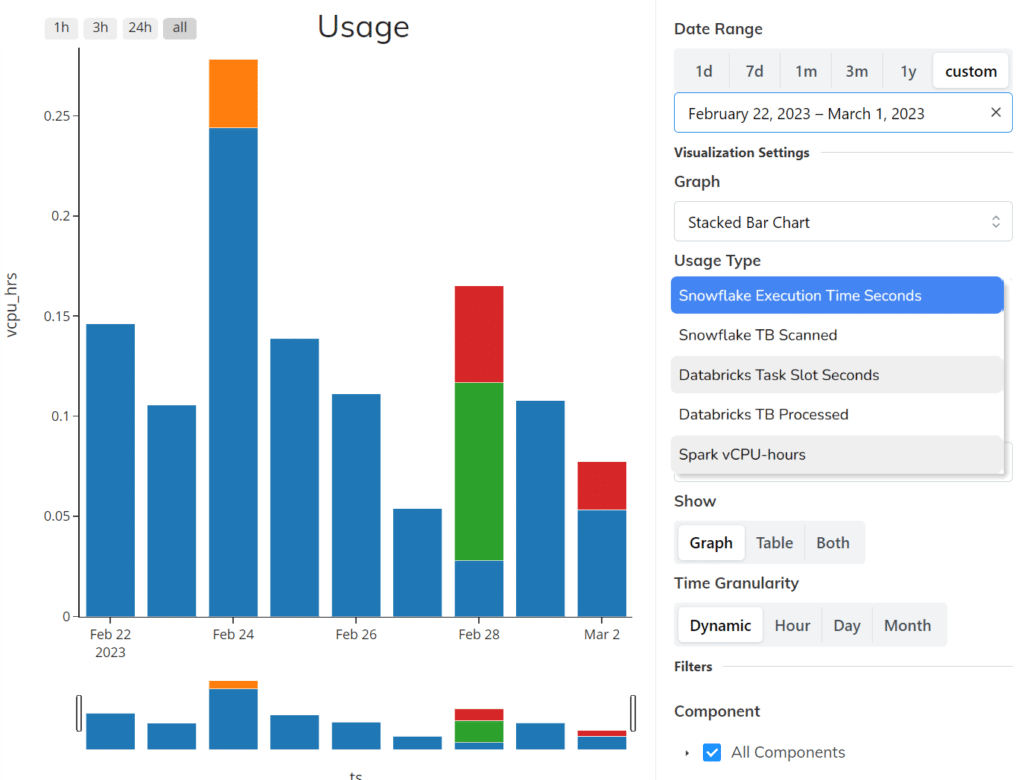
In this week’s upgrade, you get new data cloud metrics from each data cloud, which you can slice by data service or data flow:
You also get additional “Jobs Usage” and “Timeline” support in the reports. With these added features, you can isolate the costs of individual data pipelines, and tie those costs back to specific benefits — potentially reconciling those costs with revenue related to the use of the data.
Managing Environment Networks via SDK
Many engineers prefer to program the Ascend platform via the SDK, and integrate that activity into their CI/CD software development workflows. One of the functional areas covers the configuration of how Ascend connects to other systems to ingest and share data. Another covers connections by which Ascend sends workloads to your data clouds for execution and monitors their performance.
This week’s release adds SDK support to manage your environment-level connections and the credentials that secure these connections. This feature allows your engineers to include the connection process in their releases, and more completely automate and test your data pipeline deployments.
While on the topic of connectors, you have been able to ingest from IBM DB2 on iSeries/AS400 for some time. Today, we also added the ability to reverse ETL to these systems, with a write connector that includes isolation-level override. This supports the growing trend to send analytics data back into applications where they are used to enhance decision-making functions and enrich user experiences.


