


A common hurdle that many data engineering teams face is how to choose the right data replication strategy. Despite the availability of tools that offer a plug-and-play experience, the lack of a deep understanding of these strategies can lead to inefficient data management, potentially derailing your plans to create slowly changing dimensions in your data warehouse.
This article breaks down the complexities of data replication strategies in a way that’s easy to understand. By the end of this article, you’ll be equipped with the know-how to choose a strategy that not only makes sense but also aligns perfectly with your specific data needs.
Understanding Data Replication Strategies
Before delving into specific strategies, let’s take a moment to grasp what they really are and why they’re so important in data engineering.
At their core, data replication strategies are methods and practices used to create and maintain copies of your data across different systems and platforms. That can include the creation of historical data that is not available in the source system.
They play a pivotal role in ensuring data consistency, accuracy, and accessibility because they don’t just clone your data once; it’s an ongoing strategy to keep multiple, identical copies of your data in sync across various sources.
Why are Data Replication Strategies Important?
Data replication strategies are crucial for two main reasons:
- Faster Data Access: With data stored in multiple locations, users experience reduced latency and quicker access to data. This issue is typically handled by using a cloud data warehouse, like BigQuery and Snowflake, that scale.
- Support for Analytics and BI: Continuous replication keeps data in sync for analytics and business intelligence, enabling accurate, up-to-date insights.
Key Considerations When Choosing Your Replication Strategy
Choosing the right replication strategy hinges on two critical aspects: understanding your organization’s specific business needs and assessing the volume of data you handle.
Business Need
Every organization has unique requirements for how they use and analyze data. Some may prioritize immediate access for operational decision-making, while others might focus on long-term data trends and historical analysis. The key is to align your replication approach with these overarching business objectives to ensure that your data management supports and enhances your operational goals.
Data Volume
The sheer amount of data your organization handles can significantly influence your replication strategy. Large datasets bring challenges in terms of processing power and storage needs. Understanding how to manage this volume efficiently is crucial. It’s not just about handling the data; it’s about doing so in a way that balances resource use with performance, ensuring both cost-effectiveness and data integrity.
Types of Replication Strategies
Each strategy comes with its unique set of features, advantages, and challenges, making them suitable for different scenarios and requirements. Let’s explore the various types of replication strategies in detail to provide a clearer understanding of how each strategy operates.
Keep in mind that different strategies may need to be applied across different tables in the same database. Understanding the desired outcome of the end product is important and should be top of mind when evaluating each table or dataset that is ingested.
Full Resync
Full Resync involves a comprehensive replication of data from the source to the target system, essentially creating an exact copy at a given time.
Key Considerations
This strategy is most suitable for environments where data volume is relatively low, and there’s no requirement to maintain a history of changes. Its simplicity is a significant advantage for straightforward data replication needs. While easy to implement, Full Resync can be inefficient and resource-intensive for large datasets, as it involves copying the entire dataset each time, regardless of the size of changes. This strategy may be required on source tables or datasets that do not have an incremental value available, regardless of size.
Use Cases
Best for scenarios where the current data state is more important than historical changes or when hard deletes occur on the dataset.
Consider a small business with a modest-sized customer database that requires regular updates to a cloud-based analytics platform. Since the database is small and the focus is on the current state of the data rather than its history, a Full Resync strategy is ideal. It ensures that the analytics platform always reflects the latest customer information without the complexity of tracking individual changes or the need to handle any hard deletes that the source system may allow.
Incremental Load
This strategy involves replicating only the data that has changed since the last load and involves using a date or timestamp value that is updated when a change occurs, or an incremental numeric key value to load in new rows where the source table does not update previous rows.
Key Considerations
Requires a method to identify new or updated data, such as timestamps or unique identifiers. This strategy is more efficient for large datasets as it reduces the data volume being transferred. It is also used on datasets that you plan on creating slowly changing dimensions from and need to build out some historical change data. However, it does introduce complexity in tracking and managing data changes.
Use Cases
Suitable for large datasets where tracking every change isn’t necessary. Or tables that you plan on using for slowly changing dimensions downstream in your pipeline and need to start tracking daily changes.
For example, an e-commerce platform with a large inventory database can benefit from this strategy. By replicating only the items that have changed, such as new products added or prices updated since the last load, the platform ensures data freshness without the overhead of a full resync. This is also helpful for tables that are more categorical and you want to know when a product category changes but do not need the granularity of intra-day changes.
This method will not get you every change and if there are hard deletes in the source system, it will require some additional processing to ensure that they are removed. It will also require additional logic for flagging the most current record and creating some start and end dates for the previous rows.
CDC (Change Data Capture)
CDC tracks and replicates each change in the data source, including updates and deletions.
Key Considerations
This strategy requires a source system capable of supporting CDC, and it’s ideal for applications where it’s crucial to capture every change in data. It offers detailed and accurate data replication but can be demanding in terms of resource usage and system requirements.
Use Cases
Essential for systems where tracking every single change, including deletions, is critical.
A financial services firm tracking transactions in real-time would find CDC invaluable. By capturing every transaction as it occurs, the firm can maintain a highly accurate and up-to-date record of financial activities, which is needed for compliance and reporting. It is also valuable when ingesting large datasets, the changes would be much smaller than a full resync of the dataset and it would also provide deleted records that could be handled in downstream.
Snapshot
Snapshot strategy involves taking complete ‘pictures’ of a dataset at specific intervals, capturing its state in those moments.
Key Considerations
Particularly useful for data sources lacking detailed update mechanisms (like timestamps). It ensures a comprehensive capture of data changes over time but can lead to significant data accumulation, especially with large datasets.
Use Cases
Ideal for older systems or small tables that need historical tracking but lack sophisticated update mechanisms.
A small library management system, which undergoes changes like book additions or member updates, would benefit from the Snapshot strategy. Periodic snapshots of the database would suffice to track the changes, without the need for more complex replication methods. Similar to the Incremental and CDC strategies, there would be some downstream transforms to create the historical tables.
Replication Strategy
Definition
Business Need
Data Volume
Downside
Full Resync
Complete replication of data from the source to the target system
Tracking changes made to a record for isn’t required, only the current state of the record is needed
Small datasets
Inefficient for large datasets
Incremental Load
Only replicates the data that has changed since the last load based on an update date
Tracking intermediary or changes made between refreshes isn't necessary
Large datasets
Adds complexity in tracking changes
CDC
Replicates each change in the data source (database specific)
Tracking every single change, including deletions
Large datasets
Possibly resource-intensive on the source database
Snapshot
Takes periodic complete 'pictures' of a data set at set intervals
Older systems or small tables that need historical tracking but do not have an update date to use for incremental loads
Small datasets
Can lead to large volumes of data
How Ascend Handles Replication Strategies
We simplify the replication process for data engineers by offering a streamlined approach to selecting and implementing replication strategies.
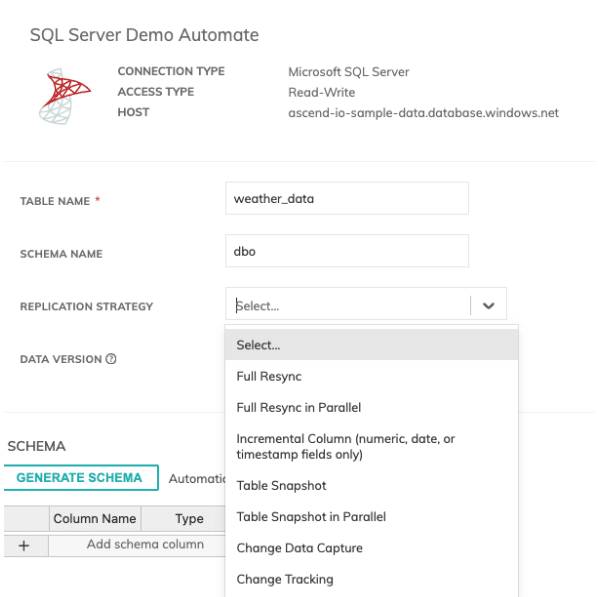
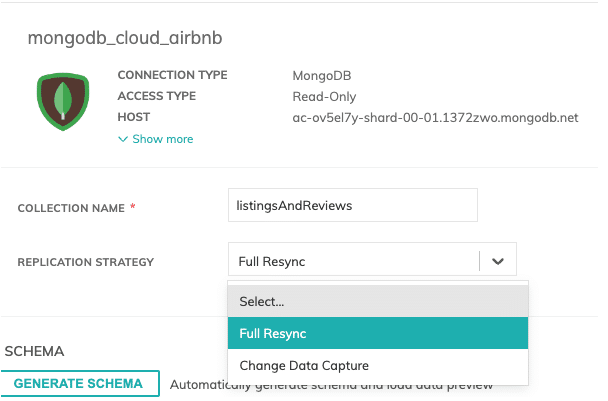
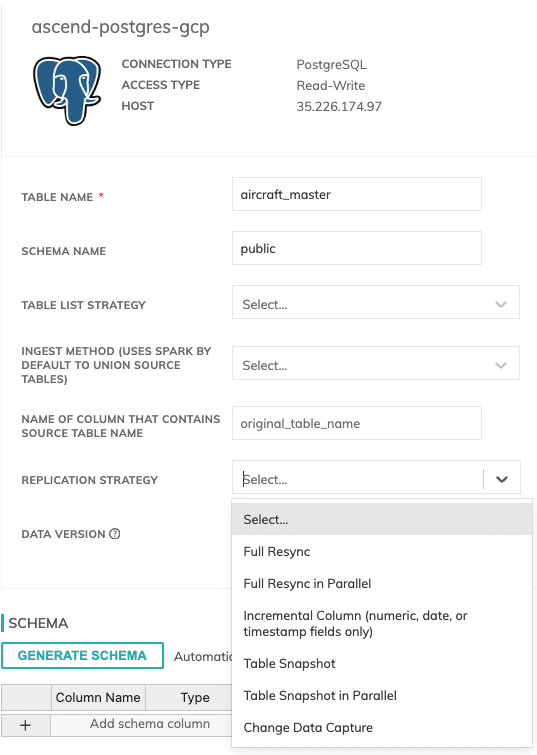
This simplicity is evident in the platform’s user interface, where users can effortlessly choose their preferred replication strategy through a dropdown menu when setting up a data connector. This feature supports all four primary replication strategies: Full Resync, Incremental Load, CDC (Change Data Capture), and Snapshot.
Below, you can see the different data replication strategies we offer depending on the source system.
Streamlining Data Replication with Partitioning
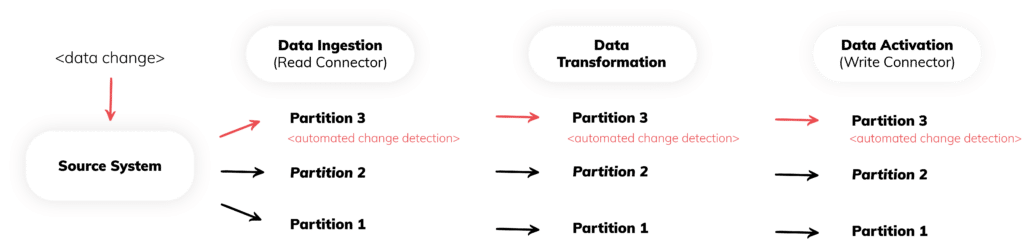
The unique aspect of Ascend lies in its integration of data partitioning with each replication strategy. Partitioning, in the context of data management, refers to dividing a dataset into smaller, more manageable segments, often based on specific criteria like time or data attributes. Ascend collects metadata about these partitions and only processes the downstream components when new data arrives.
This approach is critical for a couple of reasons:
- Efficiency in Data Processing: Partitioning enables more efficient data processing, as operations can be targeted at specific segments rather than the entire dataset. This approach reduces processing time and resource usage, especially beneficial for large datasets.
- Cost-Effective Data Management: By partitioning data, we help users minimize processing costs. This is particularly advantageous in cloud-based environments where costs are often associated with the volume of data processed.
Read More: Learn more about data partitioning.
Partitioning in Different Replication Strategies
- Full Resync: In a Full Resync strategy, each replication cycle replaces the current partition with the new copy of the dataset, ensuring that users always have access to the latest complete dataset.
- Incremental Load: With Incremental Load, we create a new partition for each batch of changes. This means that each time the read connector runs, it creates a new partition with the latest data derived from the database based on the incremental field value.
- CDC (Change Data Capture): For CDC, similar to the incremental load, we create a new partition each time the read connector runs. This partition contains only the new changes as of that time.
- Snapshot: When using the Snapshot strategy, we generate partitions at each snapshot interval, capturing the state of the dataset at specific points in time.
The built-in partitioning allows you to process only the new data that was loaded. Creating a downstream transformation that uses a merge query allows you to use any of the replication strategies above to create a current record and slowly changing dimensions.
If the data volume is large, and your final table includes joins to other tables, then you can easily create a transformation that will handle the join and then merge the final output into your dimension table. This enables you to use partitioning throughout the transformation process and only process the newest data partition when merging into the final table.


