


You are a data professional. This means that you are fully aware of the recent developments in AI and Large Language Models (LLMs). You’ve identified several complex challenges within your business that AI seems tailor-made to tackle. Exciting, isn’t it?
Yet, embarking on the AI adoption journey introduces a series of challenges, with one of the most significant being the readiness of your data platform. Is it equipped to support the sophisticated demands of AI initiatives?
In this article, we outline the essential prerequisites for an AI data platform. What capabilities should your data platform have to not only support but also elevate your AI projects?
How do you know if you are technically ready for AI?
Before we explore the specific requirements your AI data platform, let’s evaluate your technical foundation’s readiness for AI. Critical considerations include:
- Do you have the cloud capabilities necessary to scale with AI’s demands?
- Is your data environment diverse and accessible enough to fuel AI algorithms?
- Have you evaluated the elasticity of your compute resources to handle AI workloads?
What technologies must be available?
Obvious or not, having a cloud presence is generally required to leverage AI services. The elasticity and services available in the cloud are a core reason that these technologies exist, so you need to be there too. If you are in a private data center, this might be the reason you finally open up that cloud account.
If your core data systems are still running in a private data center or pushed to VMs in the cloud, you have some work to do. To take advantage of cloud-native services, some of your data must be replicated, copied, or otherwise made available to native cloud storage and databases.
This means you’ll need access to one or more technologies like blob storage, elastic compute instances, load balancing, cloud database compute, and several other services. Details of the environment are a subject for another article, but prepare yourself for your inevitable need to leverage cloud capabilities:
- Cloud Storage
- Elastic Compute
- Database Compute
- Infrastructure Automation
Now that you understand cloud infrastructure requirements for AI models, let’s talk through how to interact with them. Most AI models have very similar interfaces for integrating into your data systems. They are, typically, invoked with:
- Native SQL statements for cloud database-hosted models
- REST APIs for AI-as-a-service integrations (like ChatGPT)
- Native code libraries (python, mostly) that you invoke from your own software
Evaluating Your Data Environment
In addition to ensuring you have implemented the technologies required for AI outlined above, it’s important to also evaluate if your organization’s data environment is up to the challenge.
Most organizations, large and small, have complex data environments. This means data lives in multiple places, with a data warehouse possibly at the core, supplemented by ETL processes that funnel data into lakes, lakehouses, or warehouses.
Rough edges aside, the system “works” but it suffers from some common issues:
- New data is difficult to introduce
- Not all of the data is understood or even accessible
- Project delivery is generally slow
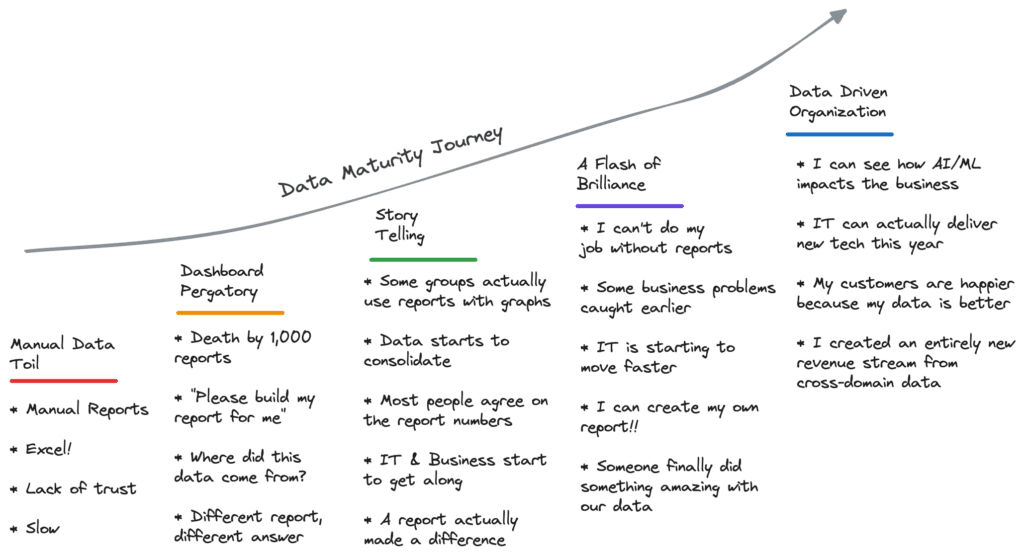
A highly useful and relatively simple way to assess your environment is to do a “Data Maturity Assessment.” Even a back-of-the-napkin assessment will help you understand what portions of your environment need updates. You don’t need to react to the assessment. Simply understanding where your data environment stands will set ‘trip-wires’ for future investments that trigger when scale becomes a problem.
AI Data Platform Requirements
AI models are hungry for data so adding new data sets needs to be simple, fast, and easy to maintain. Moreover, at a scale that matters (more than 1-2 projects), you will be tasked with integrating with more than just one type of AI model. For this reason, your data platform becomes the foundation for your AI initiatives. Below, we outline the essential requirements for such a platform.
1. Robust Data Ingestion
AI systems thrive on diverse data sources. Your platform should be equipped with robust mechanisms for data ingestion and integration, enabling seamless flow of data from various sources into the system. This capability is vital for ensuring that AI models have access to the most relevant and up-to-date information.
2. Powerful Data Transformation Capabilities
Once data is ingested, it must be processed and prepared for analysis. This involves sophisticated data transformation capabilities, including ETL (extract, transform, load) processes, data cleaning, and normalization. Such features enable the transformation of raw data into a format that’s ready for AI and machine learning algorithms to analyze.
3. Integrated Machine Learning and AI Tools
To facilitate the development and deployment of AI models, your data platform should seamlessly integrate with machine learning and AI tools and libraries. This integration allows data scientists and engineers to build, train, and deploy models directly within the platform, streamlining the AI development lifecycle and enabling faster iteration and innovation.
4. Compute Resources Optimization
AI and machine learning algorithms are compute-intensive. Your AI data platform should provide optimizations for compute resources to handle the processing power required for training complex models.
5. Native Data Automation
The number of AI models available today is small compared to what will be available in the future. Therefore, a platform that can automate and simplify adding new data, automating the data you have, and lowering the maintenance burden is required. Automation is your defense against building an ever-more-complex environment that is hard to maintain.
Data automation will provide you with the flexibility to:
- Standardize integration with the best AI models for your solution regardless of API
- Add new data feeds with configuration-based development
- Achieve scale through out-of-the-box elasticity, CI/CD automation, and observability
Data pipeline automation is essential for maintaining the agility and responsiveness needed in AI-driven operations, allowing your team to focus on strategic tasks that add value rather than getting bogged down in manual, time-consuming processes.
Build Your Own vs. Ready-Made: Data Platform Choices for AI
As we wrap up our deep dive into what it takes for a data platform to really power AI projects, there’s a big decision that lots of companies face: Should you build your own platform from scratch, or go with something that’s already out there?
Some companies decide to build their own AI data platforms thinking it will give the “ultimate flexibility” to the business solution. This approach, even when well thought out, tends to start well but grow in complexity.
At some point, the number of integrations, data models, and management of data assets overwhelms the team. Toil-based engineering activities (like CREATE/ALTER TABLE SQL maintenance) leave the team producing a much lower project throughput because time is consumed by non-value-added activities.
So, when thinking about whether to build your own platform or go with a pre-built option, it’s worth taking a step back to consider the big picture. Sure, having a custom platform sounds great, but don’t forget to factor in the long haul — keeping things running smoothly, scaling up, and making sure your team can stay focused on what really matters.
And remember, the list of requirements we’ve outlined in this article can serve as a handy guide to help you choose the right data platform for your AI projects.


