
By Anu Kirpekar, SVP of Engineering, and Kyle Osborne, Member of Technical Staff at Ascend.io
Today’s enterprises understand the importance of transforming themselves into a data-driven business. Realizing this goal requires centralizing and democratizing data for ubiquitous usage across the organization.
Today’s traditional data lakes help solve the challenges of siloed data. They have become an easy and cheap landing zone to drop data from anywhere. However, with the exponential growth of unstructured and semi-structured data, these traditional data lakes very quickly become difficult to manage to deliver value for downstream use cases quickly and securely.
The Structured Data Lake that Understands Pipelines
If you are already using the Ascend Service to build and run your data pipelines, you are getting the benefits of Ascend’s Dataflow Control Plane. You define the pipelines through declarative configurations and the Control Plane automatically executes and optimizes the pipelines across the entire data lifecycle, at scale. Backing all this is a highly optimized data store that is managed, secure, and dynamically synchronized with the pipelines that operate on it. Now this intelligent storage layer — the Ascend Structured Data Lake — is generally available for a wider range of users to benefit from its capabilities, including:
- Automated data management
- Data dependency management – as data is ingested and transformed, the system automatically manages up/downstream dependencies.
- Automatic schema inference and smart partitioning of data to leverage parallelism.
- Atomic/incremental updates and intelligent backfilling
- Consistent access to current data at any stage in the pipeline
- Deduplication of storage and processing
- Storage deduplication with built-in scalable metadata store that persists data at a partition-level, for highly efficient storage and operations.
- Incremental processing intelligence that minimizes computation to only the necessary partitions of data.
Let’s dig in more to how we designed the Structure Data Lake to make it accessible to external data processing engines, notebooks, and BI tools.
How We Implemented the Structured Data Lake
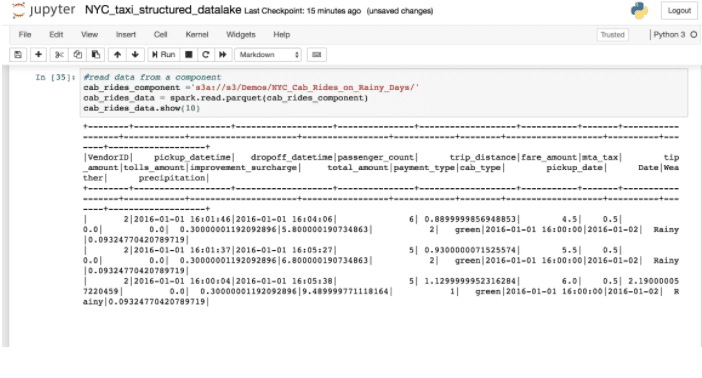
To create our Structured Data Lake, we implemented an Amazon S3 API to directly access the Parquet files that store component data in Ascend environments.
We chose an S3 API for a few reasons:
- The S3 interface is likely to work with external data processing systems
- Apache Spark can handle S3 paths using the hadoop-aws module
- Readily available open source protocol handling via MinIO
By leveraging MinIO, the implementation of an arbitrary S3 API layer is simplified:
- MinIO can handle processing the S3 protocol, so we only need to implement the logic to map between virtual paths and the underlying objects
- MinIO offers an S3 API gateway to all of the supported cloud object stores (Amazon S3, Google Cloud Storage, and Azure Blob Storage), so once the above logic is implemented, MinIO handles forwarding requests to the correct store
Before we could list objects, we needed to decide on a mapping of our internal entities to S3 paths. Using a static bucket name vastly simplified the handling of all buckets. For the virtual paths, we decided on concatenating the Data Service, Dataflow, and component ids with a delimiter, followed by virtual paths depending on the data available from the component. Data Feeds are also available directly under the Data Service. When a component has smart partitioning, we add extra layers of hierarchy to the path structure, including values from the partitioning column, so that external data processing systems such as Spark or Presto can optimize their queries more effectively.
Using MinIO to handle the S3 protocol, we are left with the problem of implementing their ObjectLayer interface. A few example methods we implemented are the following:
func (l *objectLayer) ListObjects(ctx context.Context, bucket string, prefix string, marker string, delimiter string, maxKeys int) (minio.ListObjectsInfo, error) func (l *objectLayer) GetObject(ctx context.Context, bucket string, key string, startOffset int64, length int64, writer io.Writer, etag string, opts minio.ObjectOptions) error
The function parameters provide everything we need from each S3 APR request. For ListObject, we simply need to parse the prefix string to determine what we need to list from, and query our internal metadata to generate the resulting child keys. For GetObject, we parse the key string in the same way as listing (but now require that it is complete), lookup the real S3 object corresponding to the key, then forward the parameters to a MinIO ObjectLayer corresponding to the underlying storage system.
A slight complication was handling permissions. We already associate AWS-style access keys and secrets to our service accounts, so the initial integration was simple. We can just use those as if they were AWS credentials. Inside MinIO, it tries to determine the permissions before hitting its ObjectLayer. To keep the permissioning flexible and tighten down the implementation scope, we decided to store the incoming keys in the context, and extract and verify them as part of accessing the ObjectLayer.
In practice, here is what a few full paths look like:
s3///.
s3/test/all_parts/part-00000000-b9dafcf1-2c4a-45b6-ab9f-291959ed9b33-c000000.snappy.parquet s3/////. s3/test/sdl/partitioned/year(ts)=2017/month(ts)=03/day(ts)=14/part-00000000-cf618025-ad4a-4aad-8e4e-39fd5552eeec-c000000.snappy.parquet
With this path structure, the code needed to read the data into a Spark DataFrame using the Spark shell is:
> spark.read.parquet("s3a://s3/test/all_parts") |
With smart partitioning, the intermediate path chunks will be added to the DataFrame with names equal to the string before the equal sign, and values from the piece after the equal sign.
With the virtual S3 object paths fully determined by existing internal metadata, we are able to offer a key differentiator over native S3 in that paths are guaranteed to correspond to live data. Any path seen in the virtual bucket corresponds to a component in the Ascend environment. Since the raw data writes and deletes are managed by the Ascend Control Plane, we are not currently supporting modification of data through this API, though looking to add that in the future.
Summary
With Ascend’s Structured Data Lake, all managed data is unified and dynamically synchronized with the pipelines that operate on it. For the first time, data scientists, architects, and engineers can build on top of a common data lake that automatically ensures data integrity, tracks data lineage, and optimizes performance.


